テクノロジーマネジメントUの鈴木(@szk3)です。
普段は クラウドアーキテクトとして、組織を横断してクラウド(主にAWSとGoogle Cloud)の利用を改善するための取り組みをしています。
この記事では、弊社における Cloud Center of Excellence(CCoE) の活動について紹介します。
Cloud Center of Excellence(CCoE) とは
まず、CCoEとは一言でいうと「クラウドの利用を推進させる全社横断型の組織」です。
会社の規模により組織化の形態や役割は変わると思いますが、大枠としては「クラウド利用の組織的な最適化」を目指す組織だと思います。
具体的にやることは、組織的なクラウド利用の相談・ルール化・啓蒙・教育、ガードレール構築、リソース集約化などを行うことが多いと思います。
CCoEに関しては、AWS, Microsoft, Google Cloud 各社それぞれが、CCoEについて言及しているので参考にしてください。Google Cloud には分科会があるようです。
弊社における、CCoE の定義
弊社では、CCoE をひとつのプロジェクトとして捉え、メンバーはインフラやセキュリティの有識者にワーキンググループの形で参加してもらっています。
組織化にあたり、上記のAWSによるCCoEの構築のための6つの原則を参考にしています。
また、実際の活動においては、利用の推進といった漠然とした目標では推進力が生まれないので、プロジェクトとして取り組むべきことを言語化しました。
CCoE立ち上げ時に、ビジネス的な観点(コスト・セキュリティ・アカウント台帳管理等)に対する課題意識があったため、そこを強化・啓蒙するように、以下の3つを達成したいこととして定めています。
- コスト・セキュリティ・台帳管理の3軸で、クラウドに関わるガバナンスを持続的に実施できる環境・文化の構築を目指す
- 統制実施にかかる人的負荷を軽減し、安全性・生産性ともに高水準で健全にクラウドを利用し続けられる状態を作る
- CCoE チームを組織することで、横断的なクラウドへの関心事について状況を整理し遂行をサポートする
バランスト・スコアカード
上記を元に、最終的にバランスト・スコアカードに落としてこんで、やることを整理しています。
実際に作成したバランスト・スコアカードの概要がこちらです。(※ こちらは大項目のみ抽出してあるもので、実際はもっと細かくやることが定義されています。あくまでイメージとしてご参照ください)

一点補足しておくと、監査という言葉がやや強く感じますが、ここでいう監査とは「クラウド利用状況のコスト・セキュリティ面における健全性を判断する」くらいの感覚で記述してあります。
CCoE プロジェクトでの取り組み
上記バランスト・スコアカードには細かく書いてありますが、CCoEプロジェクトで行っていることはすごく大雑把にまとめると システム開発 と チーム運営 です。
システム開発では 「改善の一歩目は可視化」と捉え、まずは 利用料とセキュリティについて組織別に可視化する為の仕組みを構築しました。
チーム運営では、クラウド利用に関する横断的な意思決定と告知、ドキュメンテーション、研修の案内、予算化ルールの策定などを行っています。
本記事では、システム開発の部分について紹介します。
CCoE システム
システムとして2つの機能を実装しています。予算管理者向けのダッシュボードと、コスト変動・異常通知です。
システムは、 AWS Cloud Development Kit(CDK) を利用し、TypeScriptでCI/CD含めインフラ周りをまるっとInfrastructure as Code(IaC)として実装しています。
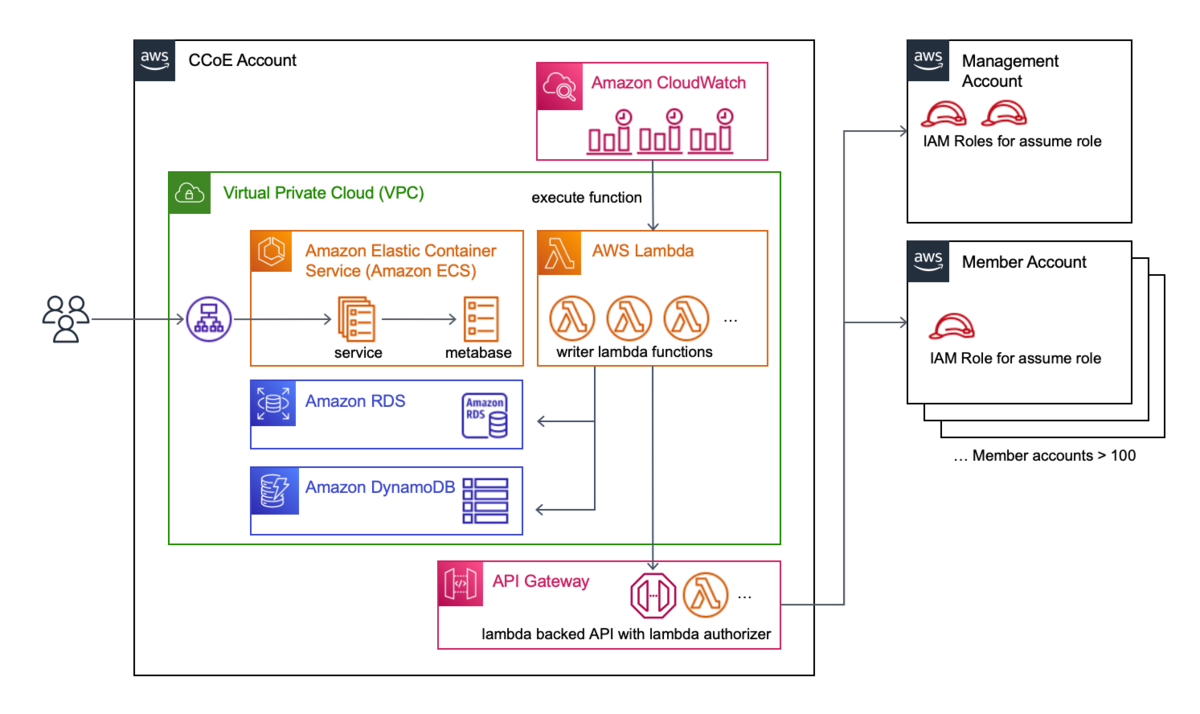
全体的な構成は、以下のような感じです。これらをCCoE用のAWSアカウントにプロビジョニング/デプロイしています。
CCoE ダッシュボード
弊社では、100以上ある各AWSアカウントの管理・運用は各組織で管轄することになっていますが、1つの組織が主管するAWSアカウントの数にはバラつきがあり、多いところでは1つの組織で10個以上のアカウントを管理しています。
そうなってくると、組織の観点でアカウントの健全性を把握しようとした際に、判断基準や確認するためのコストが変わってくるという課題がでてきます。
そこで、可視化の形を共通化することで、クラウド利用の健全性を確認するための認知コストを下げ、情報粒度を整えることを目的にダッシュボードを設計しました。
アーキテクチャ
ダッシュボードのアーキテクチャは、Amazon Elastic Container Service (Amazon ECS) + AWS Fargate で metabase タスクを実行し、データストアに AWS RDS Postgres を採用しています。
データの更新は、CloudWatch Events でスケジュールし lambda functions でデータを書き込んでいます。
データ取得
デイリーのコストの情報に関しては、バージニアリージョンの CloudWatch Metrics から取得しています。 俯瞰して傾向を見る程度であれば、CostExplorerやCURほど細かいデータの取得が必要がないので CloudWatch Metrics の情報で必要十分だと割り切っています。
各AWSアカウントの情報はOrganizationsから基本的なAWSアカウントの一覧情報を取得し、各AWSアカウントからしか取れない情報(アカウントエイリアスなど)は、それぞれのアカウントにAssumeRoleして取得しています。
また、Organizationsからダウンロードして取得したTrustedAdvisorレポートをRDSに書き込み、各組織や各アカウントといった粒度で可視化しています。
ダッシュボード
いろんなダッシュボードがありますが、いくつか主要なものを紹介します。(※ 画像に使っているデータはダミーです。)
1つ目は組織ごとのTotalEstimatedChargesのグラフになります。
上部のグラフはユニット組織としての単月合計利用料で一括で比較できます。
下部のグラフは、ユニット配下のグループが管理するAWSアカウントごとの利用料で、1日始まりで固定し直近三ヶ月+昨年同月で比較しています。 これにより、昨対や昨月でどれくらいのペースでコストが変動しているのかが誰でも同じ見方で理解できるようにしています。

以下は、組織ごとのTrustedAdvisorのエラー状態の積み上げグラフで、月毎に時系列で TrustedAdvisorのエラー数を経過観測できるようにしています。

以下は、AWSアカウントごとのコスト最適化余地を示すグラフです。
各AWSアカウントの先月の利用料(黄色)とTrustedAdvisorが提示するコスト最適化額(紫)の比較になります。
このグラフを見ることで、どのアカウントにコスト最適化余地があるのかが一目瞭然です。(もちろん全て最適化できるわけではありませんが。。。)

これらのダッシュボードの活用については、組織長が集まるミーティングの中で定期的にダッシュボードを確認し確認するような運用モデルをドキュメンテーションし、セットにして展開しています。
また、コストコントロールのため、夜間や土日は停止するように、Instance SchedulerでRDSやNatの起動管理をしています。
ECSのtask数の調整に関しては、Instance Scheduler は非対応のため lambdaでタスク数のスケジューリングを実装しています。
CCoE コスト変動通知
各AWSアカウントの中で、過去24時間のコスト増加額と増加率の上位10アカウントについて、Slack経由で定期的にレポートする通知です。
CloudWatch Event で 12時間毎に Scheduleされるので、いち早く問題に気づけるようにしています。
こちらは、独自のフォーマットで送信しているので、Chatbotとの連携はせずにWebhook経由でSlackと連携させています。
メッセージのフォーマットはこのような形です(内容はダミーです)

実際に、このアラートで週末のコスト変動異常を検知するなど一定の有用性を発揮しています。
しかし、この通知には問題点も存在します。お察しの通り、変動率や増加額を元にアラートを設定するにしても敷居値の設計が難しく、自動的なメンションを設計しづらいという点です。
なので、こちらの通知は「コスト変動・増加率の異常検出までのリードタイム」に有益性を見出し、CCoEチームがAWSアカウント全体の健全性を定常的に確認する目的で運用しています。
CCoE コスト異常検出
これは、コスト変動通知とは目的を別とし、各AWSアカウント主管の管理者が確認するものとして設計してあります。
弊社の場合、管理アカウントに請求をコンソリデートしているため、管理アカウントにて 全AWSアカウントの Cost Anomaly Detection モニター(Linked Accountタイプ) および、アラートサブスクリプション を設定しています。それらの結果は、クロスアカウントでCCoEアカウントのSNSにpublishされ、AWS ChatbotにてSlack連携させています。
コストの異常検出は組織ごとにモニターしたいとも考えたのですが、組織変更に対するモニター再作成の運用コストが高くつきそうなのと、主管するAWSアカウントがLinkedAccountsの上限10個を超えるような組織も存在するため、シンプルに1つのモニターで1つのAWSアカウントという構成にすることにしました。
しかし、モニターは100リソースまでしか作れない為、dev, prod 系のアカウントは同じモニターとしてまとめて、モニターの数を減らしています。
こちらのリソース作成用CFnテンプレートについては、管理アカウントへのCloudFormation実行のため、CCoEシステムのリポジトリとは別に管理し、動的にCFnテンプレートを作り上げる仕組みを整えています。
ハマった点としては、CloudFormation経由でリソースを作成した際に、一気に100近くのリソースを作成しようとしたため、CostExplorerのRate limit exceededに引っかかりました。そのため、各モニターとアラートサブスリプションの作成時に DependsOn属性を追加して、Rate limit を回避しています。
また、異常検出を ChatBotと連携させると、アカウントを特定する情報が AccountId しか表示されずに、パッと見でどのアカウントなのか判別が付きません。そこで、モニターと対になるアラートサブスリプションの名前に、アカウント名を追加することでどのアカウントなのか判別しやすくなるような工夫をしています。

まとめ
弊社における、CCoEの取り組みの一部を紹介しました。
クラウドは利用しつづけることで、最初はよかったとしても時間の経過とともに利用状態が負債に変化することが多々あります。例えば、時間の経過とともに意味をなさなくなったDR用のバックアップや、依存関係の問題でメンテが難しく、古いインスタンスタイプのまま運用しつづけているEC2などです。
これらの事例からもわかるとおり、クラウドの健全性は、外部環境が常に変化することを意識し、それらの進化に追従しながらコスト・セキュリティコントロールをしつづけられる状態をどのように作れるかにかかっていると思います。
CCoEへの取り組みは千差万別で、組織のサイズによってはToo muchかもしれません。しかし、逆に小さな組織であるほど、最初に整備しておくことで将来へのレバレッジが効かせられるという見方もできます。
自分が考えるCCoEとは、ただルールを作って共有するだけの組織ではなく、可能な限り自動化を推進し、ビジネスの意思決定のスピードを早めるためにテクノロジーを活用できる組織 です。
こういった取り組みは、直接的には利益を産まずコストセンターとして見られがちですが、組織のサイズに関係なく長期的な視点で有益であると自分は考えます。
本記事が、どこかの新しいCCoE立ち上げの参考になりましたら幸いです。
LIFULLでは共に成長できるような仲間を募っています。 よろしければこちらのページもご覧ください。