事業基盤ユニットアーキテクトグループのyoshikawaです。
今回のブログではLIFULL HOME'Sを構成するレガシーシステムのリアーキテクティングについて書いていきます。
2年前にリアーキテクティングプロジェクトが発足し、ソフトウェアアーキテクチャのベースにClean Architecture、言語にTypeScriptを採用し 新たなAPI(Backend For Frontend)を開発してきました。
「コードの品質」と「プロダクト開発エンジニアとのコミュニケーション」が鍵となっていた本プロジェクトですが、 このブログ記事では「コードの品質」を主題として取り組みをオムニバス的に紹介していきます。
- この記事で伝えること
- 想定する対象読者
- データフローに注目したLIFULL HOME'Sのシステム概観
- リアーキテクティングプロジェクトについて
- プロジェクト序盤:新BFFのアーキテクチャ選定、技術選定、PoC
- プロジェクト中盤〜現在:品質維持・改善
- リアーキテクティングの現在と今後:ノウハウの蓄積とリプレイスに向けて
- 終わりに
- 求人情報
この記事で伝えること
LIFULLのレガシーシステムである参照系モノリシックアプリケーションの機能を新たなAPI(Backend For Frontend)へとリアーキテクトするまでの取り組み
リアーキテクティングを支えた品質維持のためのツール、テスト、コーディング
コードの品質、ソフトウェアアーキテクチャ、リファクタリング、Clean Architectureに関するプラクティス
想定する対象読者
十数年以上稼働し技術的負債を多く抱えるWebサービスにおけるレガシーシステムの改善について知りたい人
リアーキテクティング(リアーキテクチャ)やリファクタリング、コードの品質に関する実践的な取り組みを知りたい人
コードの品質やソフトウェアアーキテクチャに興味がある人
過去のブログの紹介
プロジェクト発足の経緯や新たに開発したBFFのアーキテクチャ選定、技術選定理由などプロジェクト初期の内容は過去のブログにまとめています。
気になった方はそちらもご覧ください。(読まなくともこのブログの内容は理解できます)
データフローに注目したLIFULL HOME'Sのシステム概観
本題へと入る前に、LIFULL HOME'Sのシステムの概観をお伝えします。
BtoBtoC型の事業に類されるLIFULL HOME'Sでは多様なシステムから全体が構成されています。
toB用の書き込み系システムから物件データが入稿され、バッチ・DBなどのシステムを経て処理・蓄積された後、 物件検索機能などLIFULL HOME'Sの各種サービスで物件情報が利用可能となります。
そのデータフローを簡潔に示したシステム構成図が下記です。

なお、リアーキテクティングプロジェクトでは参照系システムの技術的負債解消を目的としているので、 その対象外となるシステムや詳細なネットワーク構成、インフラ構成については省略しています。
図中の「モノリシックアプリケーション」こそがリアーキテクティングプロジェクトでの改修対象となるレガシーシステムであり、 「新BFF」がモノリシックアプリケーション上に実装された諸機能の移行先となります。
リアーキテクティングプロジェクトについて
LIFULL HOME'Sを構成するシステムの概観をつかめたところで、本題であるレガシーシステムのリアーキテクティングおよびプロジェクトについて紹介します。
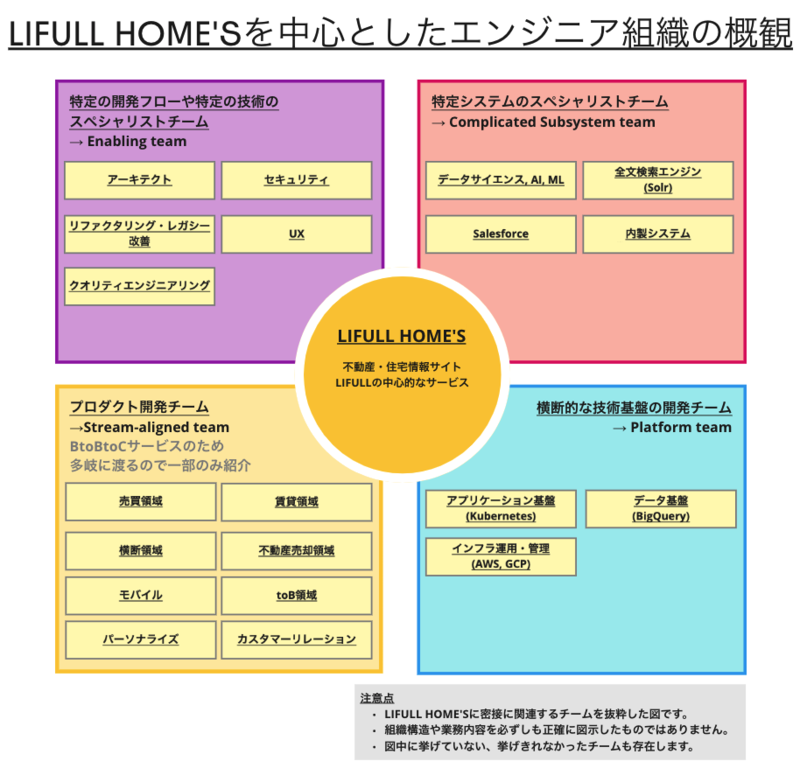
アーキテクトチーム(イネイブリングチーム)とプロジェクトの概要
筆者が在籍しているアーキテクトチーム(イネイブリングチームの一つ)の業務は2種類に分けることができます。
一つは、プロダクト開発チームで発生した設計や実装に関する問題の相談および解決策の提供です。
もう一つはプロダクト開発チームでの実行が難しい横断的な問題への取り組みです。
いずれの業務も、プロダクト開発エンジニアの生産性向上に寄与し続けることを目的としています。
そして2年前、後者の業務の一環としてLIFULL HOME'Sの参照系モノリシックアプリケーションにおける技術的負債の解消を目指すリアーキテクティングプロジェクトが発足しました。
このプロジェクトのミッションは、モノリシックアプリケーションが担っていた機能のフロントエンド部分とバックエンド部分の処理のうち、 バックエンド処理のリアーキテクティングを完了させることです。
そのリアーキテクティング先として、新たなBackend For Frontend(新BFF)の開発をすることとなりました。
新BFFへのリアーキテクティング対象機能
その膨大なLOCと影響範囲の大きさゆえ、モノリシックアプリケーションのすべてがリアーキテクティング対象になるわけではありません。
移行予定の機能を構想した後、リアーキテクティングによる事業上のインパクトや機能の特性、プロダクト開発チームとの調整ごとを加味して新BFFへ移行される機能を決定しました。

その一つが「物件一覧機能」で、「検索条件の設定・変更」から好きな条件を入力し、入力完了と同時に検索が非同期的に実行されて条件に合致した物件情報を一覧できるという機能です。
100万件超の不動産・住宅情報を取り扱っており、派生系の機能も含めて100通り以上の導線(URL)を有していることからリアーキテクティングによる対外的な影響が大きい機能です。
そして横断的に情報が検索可能という特性上、複数のプロダクト開発チームで横断的に開発されている機能でもあります。
機能の特性と深刻な内部品質の劣化
物件一覧機能では下記のような内部品質の劣化が深刻でした。
入力した物件検索条件をパースする処理や、取得した物件情報を整形する処理がモノリシックアプリケーション内のControllerやViewなどに散乱しており、コードのトレーサビリティが低い
ソフトウェアアーキテクチャや実装規約の陳腐化、責務が多過ぎるモジュール(いわゆる神クラス)の存在、コードのトレーサビリティの低さが相まって、機能改修・追加による影響範囲特定が困難
古めのバージョンのPHPで実装されており、型付けが行われておらずユニットテストの機構もないので可読性やテスタビリティが低く、潜在的なデグレーションが多い
ドキュメントが機能していないので社内有識者へのヒアリングが頻発し、新規開発者にとって実装完了までのオーバーヘッドが大きい(最悪の場合、有識者が退職しており調査が困難)
内部品質の劣化はモノリシックアプリケーションの機能にも多く当てはまりましたが、物件一覧機能においては顕著でありフロー効率の低下を招いていました。
このような理由から、モノリシックアプリケーションのみを対象としたリファクリングや新BFFへの移行を伴わないリアーキテクティングだけでは技術的負債の解消には不十分と判断されました。
エンジニア組織と横断的な機能
LIFULL HOME'Sでは「不動産・住宅情報」というドメインの関心を起点として「賃貸」や「売買」など不動産のマーケット別にプロダクト開発チームが分割されています。 そして「物件一覧機能」では賃貸用の物件や売買用の物件など、複数の不動産マーケットの情報を横断的に一覧可能です。
つまり物件一覧機能は機能単体としての技術的負債だけでなく、責務が分割された横断的な機能であることからプロダクト開発チームとの横断的な連携を要する、という性質を備えていました。
横断的な機能かつ新規APIの開発を伴うプロジェクトということもあり、開発に対するステークホルダーが多いため、 横断的な基盤開発の可能なアーキテクトチームが開発の中心となりました。
プロジェクト序盤:新BFFのアーキテクチャ選定、技術選定、PoC
技術的負債を解決すべく、Clean Architectureをベースにしたソフトウェアアーキテクチャで 新たなBackend For Frontend API(新BFF)を開発することが決定されました。
言語には学習コストの低さと型システムの存在からTypeScriptが選ばれ、OASを備えたミニマルなWeb API FrameworkとしてLoopbackが採用されました。
技術スタックの選定など、プロジェクト序盤のより詳細な内容は冒頭でお伝えした過去のブログをご覧ください。

アーキテクチャと技術選定が完了した後は、PoC(Proof of Concept)の一環として「不動産用語集」機能という実在の機能を新BFFへリアーキテクトしました。
その後検証プロセスを経て新BFFが技術的負債の解消に寄与することを確認し、プロジェクトの本格始動となりました。
プロジェクト中盤〜現在:品質維持・改善
初期段階で正しいアーキテクチャ選定や技術選定をすること、あるいは初期のベストな実装のみによって技術的負債の解消や予防になるわけではありません。
「負債」というアナロジーの通り、初期段階では事業の成長を支える資産とも言える技術基盤であっても、継続的な品質維持のための改善を欠いてしまうと負債へと転じ得ります。
継続的な改善を実施するために、内部品質(可読性に問題はないか・保守性は高いかetc)と外部品質(仕様通りに動作するか・速度劣化が生じていないかetc)の両方の点で ソフトウェアテストを徹底して行い、同時にテストがしやすくなるような改善も行ってきました。
ユニットテスト
新BFFではユニットテストとAPIテスト用のテスティングフレームワークとしてJestを使用しています。
主にテストランナーやテストカバレッジの出力、CI/CDでの自動テストという用途で利用しています。
Clean Architectureベースということもあり、モッキングについてはJestの機能を利用しておらずモック用のコードを作成しています。
コード量の少なかったリアーキテクティング初期フェーズではユニットテストの運用は順調でしたが、コード量が増えるにつれある問題が顕在化しました。
コード量増加とBFF特有処理
テストは重要です。しかしコード量が増えるにつれ、何を担保するテストなのか目的が分からなくなるほど冗長なテストコードを書いてしまう、というケースも目立ち始めました。
特に顕著だったのはDTO変換処理です。
新BFFにおける物件一覧機能用APIでは物件情報を含めたDTO(Data Transfer Object)を変換する処理が頻出します。
それらは以下のように、Domainを除く3つの層(Gateway, UseCase, Presenter)間および外部コンポーネントとのIn/Outの2通り計8パターンで分類できます。
外部データソース(=LSUDs API)のレスポンスオブジェクトをBFF内のGateway(Repository) DTOに変換する処理と、Repository DTOを外部データソースへのリクエストオブジェクトに変換する処理
Repository用DTOとUseCase用DTOとの相互変換処理
UseCase用DTOとPresenter用DTO(検索条件DTOとView Model)との相互変換処理
UI(フロントエンド、モノリシックアプリケーション)から送信されたリクエストオブジェクトをController用DTOに変換する処理、ViewModelをUIへのレスポンスオブジェクトに変換する処理

DTO変換処理はレイヤー間の責務の違いによる差分こそありますが、大部分は似たような実装となってしまいます。
下記はそのサンプルコードで、PresenterにおいてInputDtoのプロパティ(ValueObjec)からOutputDtoが要求するプロパティを作成し詰め替える処理です。
export class Presenter { constructor(private readonly input: UseCaseInputDto) {} present(): OutputDto { return new OutputrDto({ money: this.input.money ? helper(this.input.money, this.input.unit, this.input.house_type) : 'default price', houseName: // ワンライナーやヘルパー関数の呼び出しなど houseAddress: // // ワンライナーやヘルパー関数の呼び出しなど }); } helper(money?: MoneyValueObject, unit?: UnitValueObject, houseType?: HouseTypeValueObject): string { // money(金額)のフォーマット処理を行うヘルパー関数 } }
リアーキテクティング初期段階ではDTOやプロパティの変換処理は単純なものであったため、ワンライナーや即時的なヘルパー関数への分割でも問題ありませんでした。
やがてモノリシックアプリケーションに存在していた機能の移行が進むと、BFFに実装する処理も複雑になりテストのし辛さも目立ち始めました。
その辛さをカバーすべく冗長なテストコードおよび巨大なモックが増えてしまいました。
この状況を見直すべく実装パターンの見直しを行います。
モジュールの特徴を理解し、高凝集疎結合に
そもそもDTO変換処理はフロントエンドの要求に従って必要なプロパティを寄せ集め、用途に沿った加工を施し、扱いやすいよう集約する処理とも言えます。
よってフロントエンドの要求を受け入れるだけのBFFから見れば、偶発的に選ばれたプロパティに対し特に規則性のない処理を施し、一ヵ所に凝集させる処理とみなせます。
そのため注意して実装しなければ必然的に偶発的凝集・論理的凝集が生じ、凝集度の低いモジュールが出来上がってしまいます。
実際に上記のコードからわかるように、凝集度と結合度の観点でDTO変換処理には改善の余地があります。
OutputDtoのconstructorの引数の複雑さ・統一性の無さや、Presenterクラスの責務の多さを見ての通り、 実装の観点で似たような処理をただ集めた論理的凝集、つまり凝集度の低い状態が生じています。
これまでの新BFFではClean Architectureが示した責務別のレイヤー分割を忠実に採用し、dependency-cruiserによる依存関係違反の検知でモジュールの集合間(=レイヤー)の健全性は担保されていました。
しかし、一つのレイヤー内でのモジュール間の結合、および単一モジュールの凝集性は原理原則をヒントにしつつ自分たちで考える必要があったのです。
凝集度が高いモジュールを厚く、低いモジュールを薄く
凝集度とテストの辛さが相まったDTO変換処理問題の解決策として、Humble Objectパターンにヒントを見出しました。
テストの書きやすさと凝集度を両立させるべく、DTO変換処理を「凝集度を高くすべき部分」と「凝集度が低くても良い部分」に分離したのです。
「凝集度を高くすべき部分」では、テストすべきロジック(フォーマット、バリデーションなど)や再利用すべきロジックを集約させるとともに、テストカバレッジ100%を目指すなどしてテストコードを充実させます。
「凝集度が低くても良い部分」では、テストコードをほぼ書かずともTypeScriptの型システムだけで品質が担保可能となるような実装に限定します。
つまり、「凝集度を高くすべき部分」に渡す値とその戻り値を列挙するインタフェースとしてのコードを記述するだけにしました。
簡単な例ですが、具体的には下記のように実装しています。
凝集度が低くても良い部分
// 凝集度が低くても良い部分の実装、テストは薄くていい export class PresenterDtoConverter { constructor(private readonly input: UseCaseInputDto) {} // (BFF的には)偶発的に必要とされるプロパティは列挙するだけ covert(): PresenterDto { return new PresenterDto({ // テストすべき凝集度の高い処理(実際のPresentation処理)を呼び出し money: MoneyPresenter.format(this.input.money, this.input.unit, this.input.house_type), houseName: HouseNamePresenter.format(this.input.name, this.input.house_type), houseAddress: HouseAddressPresenter.format( this.input.address, this.input.house_type, ), }); } }
凝集度を高くすべき部分
// 凝集度を高くすべき部分の実装、テストを厚くする export class MoneyPresenter { private static readonly defaultPrice = 'default price'; // 引数はBFFの最小構成単位であるValue Objectだけ static format(money?: MoneyValueObject, unit?: UnitValueObject, houseType?: HouseTypeValueObject): string { // 複雑なPresentation処理 } }
凝集度に着目した解決策の効果
凝集度を起点に実装パターンを定めたことにより、テストと可読性の両観点でメリットがあります。
可読性の観点では、個別の値に関する仕様については「凝集度を高くすべき部分」を、 フロントエンドが要求する値の一覧については「凝集度が低くても良い部分」を見れば良いという共通認識が形成されます。
テストの観点では、「凝集度を高くすべき部分」は網羅性の高いテストを、「凝集度が低くても良い部分」は全体の結果の成否を確認する程度のテストを記述して テストのしやすさと保守性が担保できました。
もちろんデメリットもあり、それは実装のLOC(Lines Of Code)の増加です。
複雑なコードに慣れ親しんだ熟練者から見れば、変更前のコードこそ行数が少なくシンプルで良いと言えましょうが、今回は民主的にコードの品質を担保することを優先しました。
テストコードの冗長化に端を発する一連の問題でしたが、凝集度に注目したコード品質の向上というアプローチで解決できました。
結合テスト・回帰テスト
フロントエンド(モノリシックアプリケーション)とバックエンド(新BFF)およびデータソース(LSUDs API)との結合の際には 複数の観点で結合テスト・回帰テストを実施して参照系アプリケーション全体の品質を担保しています。
しかし、ユニットテストの機構が整備されていないモノリシックアプリケーションがテスト対象に含まれているため、CI/CDでのテスト自動実行だけでは担保しきれない項目も多いです。
そのため、専用のテスト実行スクリプトや各種ツールのグルーコードを集約したライブラリを作成し、 テスト自動実行とローカルでのスクリプト実行とを交えてテストを実施しています。
以下では、ほぼすべてのテスト項目とその効率化のための取り組みについて紹介していきます。
機能系のテスト
リアーキテクティングにおいてはその実施前後で、外部から見た挙動や機能が損なわれないことを担保することが必須です。
物件一覧機能においては表示される物件情報に差分が生じず、検索の挙動が仕様どおりで変化しないことを担保します。
その方法自体は以下の通りナイーブなアプローチです。
- リアーキテクティング前後のテスト用の環境をそれぞれ用意する
- それぞれの環境で最終的にserveされるhtmlファイルをcurlによって取得する
- htmlから不要な要素・メタデータをスクリプトでクレンジングする
- クレンジングされたhtmlのdiffの有無を検知する
- diffが生じなければテスト成功
各プロセスのスクリプト化、Playwrightによる画面操作の自動化など テスト効率化のための取り組みに加え、1.のテスト環境の用意では自社のアプリケーション実行基盤を活用し効率化しています。
テスト用の環境を用意する際には、Kubernetesベースの内製アプリケーション実行基盤により提供されているエフェメラルな開発環境を利用しています。
こうすることでテスト用環境の整備・管理の時間を削減するとともに、ローカル環境の差分など属人的な要因を排除し、再現性のあるテスト実行環境を用意できます。
テスト用環境はPull Request単位で作成可能で、Pull Request内での特定ラベル付与をトリガとしたGitHub Actionsが実行され、24時間だけ提供されます。

自社アプリケーション実行基盤については下記などのLIFULL Creators Blogをご覧ください。
パフォーマンステスト
複数のコンポーネントが結合された参照系アプリケーションでのパフォーマンステストでは、 エンドユーザーに一番近いフロントエンド部分のレスポンスタイムのパーセンタイル値(p95)をメトリクスとします。
そのパーセンタイル値とSLAを基準にした速度劣化の許容値を比較し成否を判断します。
テスト実行や計測は前述のテスト用スクリプトやエフェメラルな環境を用いて実施しています。
許容できない速度劣化を計測した際など、詳細なパフォーマンス解析が必要になった場合にはFlameGraphを活用したスタックトレーシングにより原因の特定を行います。
開発途中である新BFFにおいては0xでローカルでの解析を実施し、 それ以外の成熟したコンポーネントではDatadog APM上で解析を行いました。
負荷テスト
負荷テストではAmazon CloudWatchから移行対象機能の平常時/ピーク時アクセス数など過去の数値を収集し、 それらを基準として、秒間リクエスト数やリクエスト送信期間などを変えた複数のシナリオを作成します。
新BFFはKubernetesベースの自社アプリケーション実行基盤をインフラとして動作しているため、 そのシナリオ下の負荷でも機能が正常にアクセスできる、あるいは期待通りにスケールアウトするような Podの性能、Podのスケーラビリティなどのリソース調整を完了させることが負荷試験のゴールです。
シナリオベースで負荷テストを実施すべく、負荷テストのツールはHTTP通信用の負荷テストツールVegetaをベースに作られた Kubernetes ControllerであるVegetaControllerを使用しています。
下記のようなyamlファイルにシナリオを記述し、kubectl apply実行時の引数にシナリオファイルを指定することで実行が可能です。
# シナリオ例: 30req/sec * 60sec のスパイクテスト metadata: name: attack-bff-ephemeral spec: scenario: |- GET bff-ephemeral/v1 GET bff-ephemeral/v1?param=1&flg=true output: text option: duration: 60s rate: 30
結果解析フェーズではサクセスレートや消費メモリの推移、スケールに伴うpod数の推移などをVegetaControllerの出力とGrafanaから取得し、 各シナリオの合否を判定します。

テスト結果の蓄積
これまで紹介したテストの成否やテストケースおよびそのカバレッジ、テスト実行方法、テスト実行時の条件、発生したバグの詳細など、 テスト結果に関する事柄は内製のテスト管理ツールを活用することでダッシュボード化するとともに一ヵ所に集約しています。

このようにして過去のテスト結果を蓄積し活用しやすくすることは、長期間になるリアーキテクティングプロジェクトにとって重要なことです。
リアーキテクティングプロジェクトはストラングラーパターンというアプローチを執っているため、 対象となる機能すべての移行作業が完了するまでには複数回のリリースが必要となります。
完了には時間にして2年要するとされていました。
そして、その複数回のリリースのいずれにおいても上記のテストプロセスが含まれています。
将来のテストプロセスを効率化するという点で、過去のテストプロセスを活用できるようにしておくことには大きな意味がありました。
また知見を一ヵ所に蓄積し誰でもアクセス可能にすることで、テストに必要な知見を属人化させずにSSOT化できます。(Single Source Of Truth: 信頼できる単一の情報源)
SSOTを構築することで、プロジェクト期間中にチームメンバーの入れ替わりが発生した際でもオンボーディング時のオーバーヘッドを最小化し、プロジェクト完遂へのリスクを抑えることができます。
リリース後の品質維持と検証とメトリクス
それぞれのテストプロセス後、無事リリースされた後も品質維持のための取り組みは続きます。
内部品質と外部品質の両方の観点で技術的負債の解決を示す指標を計測し、リアーキテクティングによる影響分析を行っています。
その主たるものとして、技術的負債の可視化とパフォーマンスの可視化を紹介します。
内部品質: 技術的負債の可視化
LIFULLでは技術的負債の状況をリアルタイムに反映しているダッシュボードを構築しています。
エンジニアなら誰でも・いつでも・専用の申請なしで・同じ情報にアクセスでき、これもまたSSOTの一つです。
仕組みとしては、GitHub API、CodeClimateQuality APIの2つからコードの品質に関するデータを取得し、それらのデータをMetabaseで可視化するというものです。
可視化ダッシュボードや技術的負債に関する指標については、過去のブログをご覧ください。
以下の図のように、GitHub Repository単位で技術的負債を可視化しております。

リアーキテクティング先の新BFFは技術的負債については、具体的な数字をお見せすることはできませんがほぼ負債を抱えることなく開発できています。
技術的負債比率(図中左上のパーセンテージ)は、Code Climate Quality の MaintainabilityでA相当と低く抑えることができております。
一方、リアーキテクティング元のモノリシックアプリケーションの技術的負債については、モノリスゆえの難しさが存在します。
モノリスゆえ特定機能に絞った改善を計測することが難しく、それに加えて物件一覧機能のリアーキテクティング実施中にも別のリファクタリングプロジェクトも進行しています。
そのため、ダッシュボードだけから物件一覧機能のリアーキテクティングに絞って技術的負債解消への寄与度合いを計測することは難しいです。
しかしながら、膨大な推定修復時間(=技術的負債を返済するまでかかる時間)を要するとされたモノリシックアプリケーションの主機能の一つである物件一覧機能を ほぼ技術的負債が見られない新BFFに移行できていることから、本プロジェクトが技術的負債解消の大きな一歩になっていると言えます。
外部品質: パフォーマンスの可視化
既出の通り、外部品質についてはDatadogでのパフォーマンス可視化やGrafanaでのインフラリソース状況推移の可視化を実施しています。
これらに加え、総合的なパフォーマンス推移を計測するためにLIFULL HOME'SのWebサイトのパフォーマンスの推移をSpeedCurveで計測・可視化しています。
下記は賃貸物件一覧機能(物件一覧機能の一つ)の昨年のパフォーマンスの推移を示した図です。

外部品質の点でも別プロジェクトによる軽微な影響は存在し、実際の数字をお見せすることはできませんがリアーキテクティングによってパフォーマンスは維持どころか総じて改善できています。
リアーキテクティングの現在と今後:ノウハウの蓄積とリプレイスに向けて
2022年1月現在、かつてモノリシックアプリケーションに存在した物件一覧機能の多くが新BFFへと移行されました。
プロジェクト発足当初のアーキテクチャ選定、技術選定から2年近くが経過した後も、新BFFおよび物件一覧機能においてインシデントはほぼ発生せず安定稼働を実現できています。
リアーキテクティングプロジェクトはもう少し続きますが、新BFFへのリアーキテクティングも終盤に差し掛かり、今春に予定していた移行作業が完了する見込みです。
しかし、事業の成長の陰に蓄積され続けたモノリシックアプリケーションの技術的負債の完全解決にはまだまだ時間がかかり、2年の時間をかけたリアーキテクティングプロジェクトはその一歩に過ぎません。
とはいえ、リアーキテクティングプロジェクトで得られたコード品質やアーキテクチャに関するノウハウとそれらを活用した後発プロジェクトの存在もあり、可視化ダッシュボード上の数字ほどは途方もない作業ではないと言えます。
フロントエンド部分を含めてモノリシックアプリケーションのリプレイスを実現すべく、プロダクト開発チームによるリファクタリング・リアーキテクティングおよび品質維持が促進されゆく予定です。
終わりに
技術的負債を解決および予防し、継続的にフロー効率の高い開発を行うためにも内製ソフトウェアアーキテクチャを含めた「コードの品質」のための取り組みは今後も続きます。
最後に、今後のLIFULL HOME'Sのシステムにおけるコード品質の今後の展望と、リアーキテクティングプロジェクトを通じて見えたデータの課題をお伝えします。
Clean Architectureの考えを継承しつつ、アーキテクチャ内製化へ
Clean Architectureをベースに開発が開始した新BFFのソフトウェアアーキテクチャですが、 アーキテクトチームではClean Architectureが伝えているものはあくまでプリミティブな原理原則であるという認識で開発しています。
凝集度の例にあるように、実際にどのように実装しパターン化するかは機能の特性をもって判断しています。
そのパターンの中には、凝集度の項でお伝えしたような比較的一般化可能なものから、LIFULL独自の制約に由来したことで場合によってはアンチパターンと呼ばれてしまうものもあるかもしれません。
また、新BFFのソフトウェアアーキテクチャは物件一覧機能のリアーキテクティングを行ったプロジェクトおよびその当事者であるアーキテクトチームだけで完結するものではありません。
コードの品質向上に対する成果が認められ、複数の新機能実装プロジェクトや別のリアーキテクティングプロジェクトにおいても新BFFのソフトウェアアーキテクチャが採用・応用されています。
今後は幅広いプロジェクトでの利用に耐え得るように、Clean Architectureの考えを継承しつつ、LIFULL独自のパターンとノウハウを備えた内製ソフトウェアアーキテクチャを正しく普及させ運用することが求められます。
内製ソフトウェアアーキテクチャを普及させる仕組みと教育
内製ソフトウェアアーキテクチャの普及のためには、ドキュメンテーションや開発者コミュニティづくりなど、 プロダクト開発チームが自律的に開発可能になることを補助するための仕組みおよび教育が必要です。
後日公開予定のブログにて、その仕組みづくりなど「プロダクト開発エンジニアとのコミュニケーション」においてアーキテクトチームが実施したことを詳しくお伝えする予定です。
理想とこれからの課題

上記は冒頭に載せたデータフロー図とほぼ同じですが、リアーキテクティングプロジェクト等のモノリシックアプリケーション上の技術的負債解消の取り組みによって、参照系アプリケーション開発の分散統治が可能になった将来的な理想形です。
開発の度に全社的な調整を要することもあるモノリシックアプリケーションから、部署レベルでの自治(self-service)が可能な単位で機能が切り離される、という構図です。
その端緒であり、技術的負債解消という当初の目的を果たしつつあるリアーキテクティングプロジェクトですが、self-serviceの障壁となり得る課題がプロジェクトを通じて顕になりました。
それがデータ整備です。
図中でLIFULL HOME'Sのシステムを「データ分析システム」・「データ利用システム」・「データ提供システム」の3つに分類しましたが、 その3つを通じて運用されるデータの品質には依然として課題があり、整備する余地があると考えています。
データ整備の課題とその解決のために
データ分析・活用の文脈で語られることの多いデータ整備ですが、LIFULLのように一定以上の規模と歴史を持つ業務用アプリケーション開発においてもデータ整備の課題は顕著であると考えています。
その中でリアーキテクティングプロジェクトにおいて体感した課題はデータの発見可能性です。
既存システムの理解のためにコードリーディングを行う機会は多々ありましたが、 改修対象のモノリシックアプリケーションのコードリーディングに加え、大元のデータソースであるLSUDs APIやデータベースを対象とした利用すべきデータの発掘やデータ仕様調査にも多くの時間を要しました。
つまり、「データ提供システム」で生成されるデータが「データ利用システム」で利用可能になるまでに属人的な取り組みが必要だったのです。
リアーキテクティングプロジェクトとは別の調査で判明していることですが、上記以外にも以下のような課題があると考えています。
分析用データ(OLAP)と、アプリケーション用データ(OLTP)の一貫性の問題(→「データ分析システム」と「データ利用システム」間のデータ相互運用性が低い)
特定のアプリケーション向けに加工されたデータを再加工する必要性の存在(→「データ利用システム」間のデータ相互運用性が低い)
再利用すべき大元のデータおよびそのデータに至る経路が見つけられない、見つけられないので似たようなデータを使うか自作してしまう(→システムを通じたデータ系統樹:Data Lineageの問題)
データ整備が起因する課題はドキュメンテーションや有識者へのヒアリングなど、静的なコンテンツの整備や属人的な努力によって一時的には解決可能な問題です。
しかし、大規模なデータを抱えるLIFULLにおいて持続可能性のある解決策を実現するためには、データをマネジメント・発見・一覧可能な基盤づくりが必要と考え現在はその検証が進行中です。
求人情報
LIFULLではエンジニアの募集をしております。
このブログで紹介させていただいたような、Clean ArchitectureとTypeScriptで堅牢なアプリケーション開発を行う業務も可能ですので、募集中の職種や詳細などは下記をご覧ください。