LIFULL札幌開発拠点で働くエンジニアの村田です。
本エントリーはLIFULL Advent Calendar2021、12月20日の記事になります。
私が働く札幌では、この時期雪が積もり始め寒さも厳しくなってきます。 東京本社から札幌に職場を移してから早3年が経ちましたが、ようやく札幌の寒さにも慣れてきた今日この頃です。
私が所属する部署は東京本社と札幌支社のエンジニアで構成された部署になり、社内では通称KEELチームと呼ばれています。
KEELとは、LIFULLグループ全体で利用することを目的としたKubernetesベースの内製のアプリケーション実行基盤です。 詳しくは以下のエントリーをご覧ください。
KEELはLIFULLのアプリケーションの開発・運用に必要な多くの機能を提供しています。 本エントリーでは、KEELが提供する監視基盤の一部であるURI毎のサクセスレート可視化機能のお話しをしたいと思います。
背景
LIFULLの主要サービスであるLIFULL HOME'Sは20年以上続いているサービスであり、非常に多くのコンテンツを保有したサービスに成長しています。
このモノリスな巨大アプリケーションを運用するにあたり、障害検知に関するとある問題が発生していました。
ことLIFULL HOME'Sにおいては、サイト全体に影響を及ぼすような、ある程度規模の大きい障害であればすぐに検知できるのですが 特定のコンテンツのみで障害が発生した場合、アプリケーション全体のサクセスレートが閾値まで押し下がらずアラート通知されないまま、その不具合が見過ごされてしまうといった事がありました。
URI毎のサクセスレートの開発
KEELチームが問題解決のアプローチとして導き出した答えは、URI毎にサクセスレートを確認できるダッシュボード機能の開発でした。 説明するよりもまずは現在運用されている実物の画面を見てもらう方がイメージがつきやすいと思います。

アプリケーションのダッシュボードの上部には、ステータスコード毎のRPSや、パフォーマンスのパーセンタイル値、その下には各URIのRPS・パフォーマンス・サクセスレートが表示されています。サクセスレートが正常であれば緑で表示されますが、低下している状態だと赤くハイライトされ一目でどのコンテンツに異常が起きているかわかるようになっています。
上記のイメージに表示されていませんが、CPUやメモリのリソースの状態やPod数の推移などのパネルも用意されており、アプリ開発者はこのダッシュボードを見るだけでアプリケーションの状態を把握することができます。アプリケーションによっては、アプリケーションサーバーのworker数なども確認することができます。
どのように実現したか
URI毎のサクセスレートの可視化は、以下のようなステップで実現しています。
- コンテナから出力されたアクセスログをFluentdにて集計しPrometheusにメトリクスを送信
- ダッシュボードで使用するメトリクスをRecording Ruleで予め集計して用意しておく
- Grafanaのダッシュボードで集計したメトリクスを可視化する
- アラートルールを設定する
まず、コンテナが出力したアプリケーションのアクセスログをFluentdにて集計し、Prometheusにメトリクスを送信しています。
ここで作成されるメトリクスはラベルにURIやHTTPメソッドを持ち、リクエストを識別できるようにしています。 メトリクスタイプはヒストグラムを利用しており、パフォーマンスをパーセンタイル値で表示するのに適した形になっています。
ここで注意したいのが、全てのURIをラベルに含んでしまうとカーディナリティが高くなりPrometheusのリソースを大量に消費してしまいます。 URIにIDといったパラメータが含まれている場合、それだけで無数のURIが生まれてしまいますので、そうならないように、アプリケーション毎に「ラベルとして登録できるURIのプレフィックスリスト」を定義しておき、集計対象となるURIを限定しています。
これで必要最低限のメトリクスの準備はできましたが、実際はこれをベースに様々なPromQL式を評価して目的とするデータを得る必要があります。PrometheusにはあらかじめPromQL式を評価しその結果を新たなメトリクスとして保持することができるRecording Ruleという機能があります。この機能を利用し、必要なデータを前もって計算しておくことで処理の高速化をはかっています。
メトリクスの可視化にはGrafanaを利用しています。
Grafanaのダッシュボードは、UIを利用して手動でパネルを組み合わせて構築することも可能ですが、アプリケーション毎に手動で構築するのは運用の面から考えても避けたいものです。
そこでGrafanaのダッシュボードをJsonnetでコード管理することにしました。 当初Jsonnetの用意は開発者が手動で行っていましたが、コードジェネレーターであるkeelctlが開発されてからは、上記のJsonnetファイルがコマンド一発で自動生成されるようになり、容易にダッシュボードの作成ができるようになりました。
最後はアラートの設定です。 閾値を調整したり、アラート発生時のRunbookを設定することがURIそれぞれで可能になりました。アラートルールも上記と同様にJsonnetで管理されており、keelctlを利用して開発者は容易にアラート設定を行うことができます。
何が変わったか
アプリケーションのURI毎のサクセスレートが可視化された結果、どのような変化がLIFULLにもたらされたでしょうか?
一番大きく変わったのは、今まで見えてこなかった細かな不具合が見つかるようになりました。 URI毎にサクセスレートを計測できることになったことで、それぞれのURI単位でアラートを通知できるようになりました。
今まではサイト全体のサクセスレートが閾値を割らないとアラートが通知されず、細かい不具合は露呈されませんでしたが パス毎にアラートを飛ばすことができるようになったため、今まで見過ごされてきた多くの不具合を見つけることができました。
結果LIFULLのサービスの品質向上にかなり寄与できたと思います。
さらに、障害調査の点でも効率が上がる結果となりました。 従来、障害が発生した際に、まずは影響範囲を調査する必要がありましたが、ダッシュボードを確認するだけでアプリケーションのどの部分でエラーが発生しているのかすぐに把握できるようになっています。
URI毎のアラートにRunbookを設定できるようになっていますので、例えばDBにアクセスしているコンテンツでサクセスレートが低下しているなら、対応するURIのアラートにDBの障害を疑うといったヒントを記述しておくといったようなことができ、調査効率が飛躍的に向上しました。
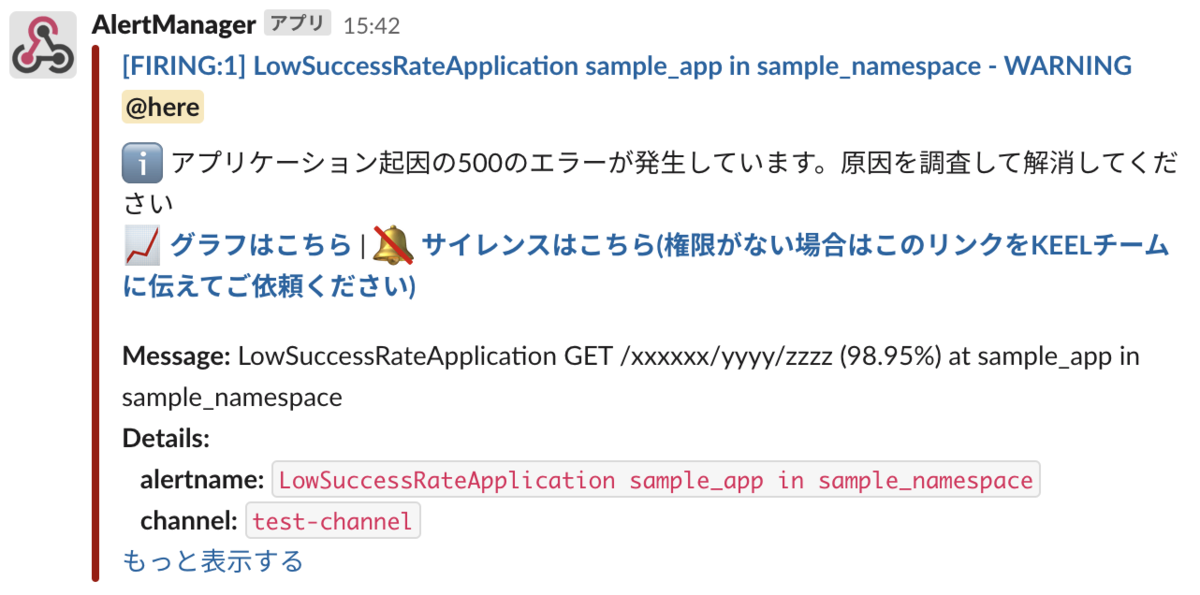
障害がどのURIで発生しているのかを明確にしたことで、障害対応のフローにも変化が起きました。
LIFULL HOME'Sは一つのアプリケーションに多くのコンテンツが含まれており、それを管轄する部署が多岐に渡ります。 仮に障害が発生した場合、どこの部分で障害が発生したかで対応する部署が変わってきます。 KEELチームが障害を検知したとしても、それをどこの部署に報告すれば良いか判断が難しい場合がありました。
そこでURIのパターンによって管轄部署を定義することで、障害発生時のエスカレーションを無駄なく行うことができるようになりました。 具体的には、障害が発生した際にBot経由でGitHubに障害チケットを作成し、その対象URIに対応した部署のラベルを自動で付与します。 開発者は自分が所属する部署のラベルが付与された障害チケットが発行されると、その障害の調査・解消にあたる、といった障害対応フローが確立されるようになりました。

まとめ
LIFULLを支える監視基盤を構成する要素の一つであるURI毎のサクセスレート可視化について紹介させていただきました。
アプリケーションのURI毎に細かい情報を可視化することで、今まで見過ごされてきた思わぬ不具合を見つけることができ、障害発生時にも効率良い調査が可能になりました。
障害対応フローも整備され、今では細かい不具合も見逃さず検知し、うまく対応できるような体制が構築されました。
結果、URI毎のサクセスレート可視化を起点にBPRに繋がる形にまで発展させられたことを嬉しく思います。
KEELチームはLIFULLが掲げる「あらゆるLIFEを、FULLに。」の実現に向けて、LIFULLのものづくりを加速させるためのプラットフォームを革進し続けています。今回お話しさせていただいた機能以外の取り組みについては、以下のエントリー一覧をご覧ください。
最後にLIFULLの採用について少し触れさせてください。
LIFULLでは、「あらゆるLIFEを、FULLに。」に実現を目指して共に働いていただける仲間を募集しています。 カジュアル面談という形で、まずは気軽にお話をさせていただく、ということも可能ですので、ご興味がある方は以下のページをご覧ください。