こんにちは!テクノロジー本部事業基盤ユニット改善推進グループ所属の王です。
現在はLIFULL HOME'Sの各種サービスが参照するデータベースをOracleからPostgreSQLに置き換えるDB移行プロジェクトの業務を担当しています。
今回のブログのテーマは、DB移行プロジェクト内の課題を解決するため、PostgreSQLデータベースの拡張機能oracle_fdwの使用検証および検証中の気付きです。
DB移行プロジェクトの詳細については、こちらのブログを参考にしていただけるとうれしいです。
www.lifull.blog www.lifull.blog www.lifull.blog
DB移行プロジェクトの課題
oracle_fdwを使用検証するきっかけとしてはDB移行プロジェクトにある課題の解決です。
課題について説明します。
DB移行作業におけるテーブルの依存関係
DB移行プロジェクトで移行する予定のさまざまなSQLの中には、一つのSQLで複数のテーブルにデータ参照している場合があります。例としては複数テーブルの結合があるSELECT文、テーブルの参照結果を別テーブルにINSERTするなどです。
これらのSQLによって、DB移行作業におけるテーブル間の依存関係が発生しています。たとえば、テーブルAとテーブルBが同じSQLに使われる場合、テーブルAへのDB参照を完全に移行するため、テーブルBへのDB参照を変更する必要があります。
複雑なテーブル依存関係が課題
複雑なテーブル依存関係はDB移行作業に支障を与えて移行プロジェクトの課題となっています。
今回DB移行プロジェクトにさまざまな複雑なSQL文を移行する必要があります。SQLに使われるテーブルは数多くあり、DB移行におけるテーブルの依存関係は非常に複雑となっています。
移行する予定テーブルの中で、仮に一つのテーブルのDB参照が移行先に変更することが難しい場合、依存関係を持つほかのテーブルにも影響してしまい移行できなくなります。
上記の状況は実際にプロジェクト内で発生しています。複雑なテーブルの依存関係によって、部分的な移行進捗の遅れはプロジェクト全体の進捗に大きく影響する可能性があるため、現在プロジェクトの一つの課題となっています。
oracle_fdw
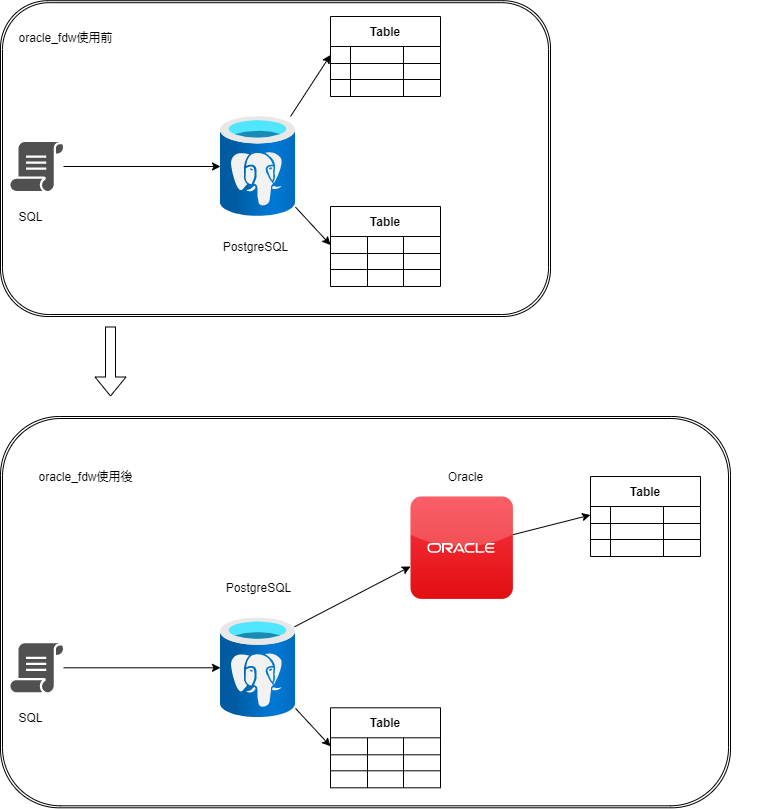
上記テーブルの依存関係による影響を減少させるために、oracle_fdwというPostgreSQLの拡張機能を導入することを検討しています。
oracle_fdwとは?
oracle_fdwはPostgreSQLの拡張機能の一つです。
FDWとは、外部データラッパー(Foreign Data Wrapper)の略称です。Postgresにはさまざまな外部データラッパがあり、Postgres以外のデータソースをアクセスする仕組みです。oracle_fdwはその中の一つです。
Oracle上のテーブルやビューをPostgreSQLの外部テーブルにマッピングすることにより、PostgreSQLからOracleデータベースにアクセスして、データを取得することが可能となります。
oracle_fdwに関する詳しい説明は以下の資料が参考になると思います。
また、oracle_fdwはOSSとしてGitHubに公開されています。関連情報も以下から取得できると思います。
なぜ課題の解決に役立つ?
oracle_fdwを使用することで一つのSELECTで複数のテーブルをJOINしている場合でも、異なるDBインスタンスにあるテーブルどうしをJOINしてデータを取得できます。
この特性を活かすことによってSQLを移行する時に、SQLに使われるテーブルを全部移行先のPostgreSQLにデータ参照変更が必要という制限はなくなります。
移行する予定テーブルの中で、仮に一つのテーブルのDB参照が移行先に変更することが難しい場合、依存関係を持つほかのテーブルにも影響してしまい移行できなくなります。
すなわち、上記のようにしばらく移行が難しいテーブルが存在する場合でもそのテーブルの参照だけOracleのままにしてほかの依存テーブルはPostgreSQLに参照することとなります。
検証作業での気付き
oracle_fdwはまだ現段階使用の検証しており、実際にプロジェクト内で使用するのが始まっていないですが、検証作業をしてみていくつか気付きがあったので共有します。
PostgreSQLにインストール
oracle_fdwのインストールは以下のページの記載を参照することがお勧めです。
注意点は下記となります。
oracle_fdwの使用にはPostgreSQLのバージョンが9.3以上を要求しています。AWS RDSの場合、PostgreSQL 12.7、13.3、14およびその以降のバージョンしか導入できない制限があります。バージョン関連の情報はAmazon RDS でサポートされる PostgreSQL のエクステンションに参照可能です。
OracleへのアクセスにはPostgreSQLサーバにOCI(Oracle Call Interface)ライブラリのインストールが必要です。バージョン11.2以上を要求しています。
使い方
画像引用元:https://www.postgresql.fastware.com/postgresql-insider-fdw-ora-bas
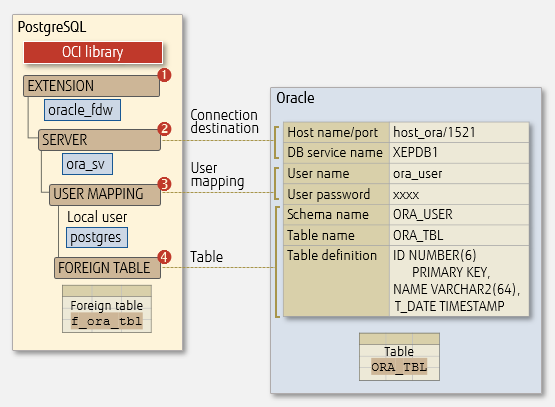
上記の図に示すようにPostgreSQLの外部テーブルとOracleのテーブルのマッピング関係を設定する上で、PostgreSQLからOracleテーブルのデータをアクセスできます。
連携先のOracleデータベースの各種情報を利用して、下記の手順で設定する。
oracle_fdwのエクステンション(EXTENTION)の作成
CREATE EXTENSION oracle_fdwでPostgreSQLのエクステンションを作成する必要があります。外部サーバの作成
Oracleのホスト、ポート、データベース名を格納する外部サーバを作成する
CREATE SERVER ora_sv FOREGIN DATA WRAPPER oracle_fdw ## ホスト、ポート、データベース名を設定する OPTIONS (dbserver 'host_ora:1521/XEPDB1')PostgreSQLユーザーに外部サーバの使用権限をつけることも必要です
GRANT USAGE ON FOREIGN SERVER ora_sv TO postgres;ユーザーマップの作成
OracleユーザーとPostgreSQLローカルユーザーとのマッピングする
## Oracleデータベースのユーザー名、パスワードを設定する CREATE USER MAPPING FOR postgres SERVER ora_sv OPTIONS ( USER 'ora_user', PASSWORD 'xxxx');ユーザーマッピングすることで、Oracleユーザーと同じアクセス権限をもらう
外部テーブルの作成
最後、PostgreSQLに外部テーブルを作成して、Oracleテーブルとのマッピングを設定する
CREATE FOREIGN TABLE f_ora_tbl( ## 主キーカラムはkeyオプションで設定する id int OPTIONS (key 'true'), name varchar(64), t_data timestamp) ## スキーマ、テーブルを設定する SERVER ora_sv OPTIONS (SCHEMA 'ORA_USER' , TABLE 'ORA_TBL');テーブルのマッピングには以下の注意点があります。
- テーブルカラム定義は、Oracle側のテーブルカラムと同じ種類のデータ型を定義する必要があります。異なるデータ型を指定する場合、oracle_fdwが自動的にデータ変換が行います。
- OracleとPostgreSQLテーブルカラムのマッピングはカラムの順序をそれぞれ対応させる、外部テーブル作成する時はカラムの順番は要注意です。カラムの順番が間違っている場合、正しいデータアクセスが行われない可能性があります。
- Oracle側のテーブルデータを更新する場合は、主キーカラムすべてにkeyオプションの設定が必要です
SQLパフォーマンスへの影響
oracle_fdwを使うSQLを発行する場合、SQLの実行にOracleとPostgreSQL間の通信が発生します。ローカルのテーブルアクセスと比べて、データベース間の通信速度、通信容量の制限に影響があるため、SQLのパフォーマンスには影響する場合もあります。
連携先のOracleデータベースから大量のデータを取得する場合、SQLのパフォーマンスが落ち、PostgreSQLおよびOracleにも負荷をかける可能性があるため、実際の使用には要注意です。
PostgreSQL外部テーブルへのアクセスがある2つのSQLから説明したいと思います。
SQL A
select count(*) from ora_tbl s join tbl g on s.id=g.id and (s.id=952 or s.id=948) Execution Time: 5.935 ms
SQL B
select count(*) from ora_tbl s join tbl g on s.id=g.id and (g.id=952 or g.id=948) Execution Time: 2656.699 ms
* ora_tblは外部テーブル、tblはローカルテーブル。
上記2つのSQLは外部テーブルとローカルテーブルの結合を行い、絞り込み条件にあうレコード数を取得しています。
SQLの実行結果は一致していますが、SQL Aの実行時間はSQL Bより明らかに短いです。
SQLの実行計画から原因を特定すると、以下のことが分かります。
SQL A
explain analyze select count(*) from ora_tbl s join tbl g on s.id=g.id and (s.id=952 or s.id=948) "Aggregate (cost=24004.50..24004.51 rows=1 width=8) (actual time=5.837..5.838 rows=1 loops=1)" " -> Nested Loop (cost=10000.29..24002.00 rows=1000 width=0) (actual time=0.430..5.566 rows=1153 loops=1)" " -> Foreign Scan on ora_tbl s (cost=10000.00..20000.00 rows=1000 width=14) (actual time=0.407..3.479 rows=1153 loops=1)" " Oracle query: SELECT /*727d818c0e8c5e5fc8c1ba25f14f1951*/ r1."COL_1" FROM "ORA_TBL" r1 WHERE ((r1."ID" = 952) OR (r1."ID" = 948))" " -> Index Only Scan using pk_tbl on tbl g (cost=0.29..4.00 rows=1 width=6) (actual time=0.001..0.001 rows=1 loops=1153)" " Index Cond: (id = s.id)" " Heap Fetches: 706" "Planning Time: 1.569 ms" "Execution Time: 5.935 ms"
SQL B
explain analyze select count(*) from ora_tbl s join tbl g on s.id=g.id and (g.id=952 or g.id=948) "Aggregate (cost=20019.19..20019.20 rows=1 width=8) (actual time=2656.574..2656.578 rows=1 loops=1)" " -> Hash Join (cost=10016.56..20019.18 rows=1 width=0) (actual time=276.345..2656.376 rows=1153 loops=1)" " Hash Cond: (s.id = g.id)" " -> Foreign Scan on ora_tbl s (cost=10000.00..20000.00 rows=1000 width=14) (actual time=0.400..2549.151 rows=717509 loops=1)" " Oracle query: SELECT /*90e1158c8e451061bc34a219bd77fa69*/ r1."ID" FROM "TBL" r1" " -> Hash (cost=16.53..16.53 rows=2 width=6) (actual time=0.028..0.030 rows=2 loops=1)" " Buckets: 1024 Batches: 1 Memory Usage: 9kB" " -> Bitmap Heap Scan on tbl g (cost=8.60..16.53 rows=2 width=6) (actual time=0.023..0.027 rows=2 loops=1)" " Recheck Cond: ((id = '952'::numeric) OR (id = '948'::numeric))" " Heap Blocks: exact=2" " -> BitmapOr (cost=8.60..8.60 rows=2 width=0) (actual time=0.017..0.019 rows=0 loops=1)" " -> Bitmap Index Scan on pk_tbl (cost=0.00..4.30 rows=1 width=0) (actual time=0.013..0.013 rows=1 loops=1)" " Index Cond: (id = '952'::numeric)" " -> Bitmap Index Scan on pk_tbl (cost=0.00..4.30 rows=1 width=0) (actual time=0.004..0.004 rows=1 loops=1)" " Index Cond: (id = '948'::numeric)" "Planning Time: 1.377 ms" "Execution Time: 2656.699 ms"
実行計画のForeign Scanの部分を注目してください。
SQL A
" -> Foreign Scan on ora_tbl s (cost=10000.00..20000.00 rows=1000 width=14) (actual time=0.407..3.479 rows=1153 loops=1)" " Oracle query: SELECT /*727d818c0e8c5e5fc8c1ba25f14f1951*/ r1."COL_1" FROM "ORA_TBL" r1 WHERE ((r1."ID" = 952) OR (r1."ID" = 948))"" -> Foreign Scan on ora_tbl s (cost=10000.00..20000.00 rows=1000 width=14) (actual time=0.407..3.479 rows=1153 loops=1)"
SQL B
" -> Foreign Scan on ora_tbl s (cost=10000.00..20000.00 rows=1000 width=14) (actual time=0.400..2549.151 rows=717509 loops=1)" " Oracle query: SELECT /*90e1158c8e451061bc34a219bd77fa69*/ r1."ID" FROM "TBL" r1"
主な実行時間の差はForeign Scanから生じます。
Foreign ScanはOracleのアクセスする時に発生します。SQL Aの場合、Foreign Scanから取得するレコード数は1153です。SQL Bの場合、Foreign Scanから取得するレコード数は717509です。
結論として、oracle_fdwの使用する時、OracleとPostgreSQLの通信データ量はSQLのパフォーマンスに大きく影響します。
oracle_fdwを使う時のSQLパフォーマンスが気になる場合、Explain文でSQLの実行計画を分析してSQLチューニングすることがお勧めです。実行結果にあるForeign Scanの回数およびレコード数を抑えるSQLチューニングはSQLパフォーマンスの向上に役立つと思います。
oracle_fdwを使うSQLの性能を影響する要因はほかにもあるため、気になる方は下記の記事を参考できると思います。
Oracleデータベースにアクセスする ~oracle_fdwを使いこなすために~
まとめ
以上PostgreSQLのoracle_fdw拡張機能を検証してみた話でした。読んでいただきありがとうございます。
まだ実際にDB移行プロジェクトには導入していないため、導入後のメリットとデメリットまたはプロジェクトへの影響はまだ不明です。今後また機会があればブログを書いて共有したいと思います。
また最後にLIFULLでは一緒に働く仲間も募集しているので、よろしければこちらも併せてご覧ください。