KEELチームの相原です。
今回は流行に乗ってLLM(Large Language Models)の話です。
とは言うもののLLMは単なる流行ではなく新たなパラダイムと言っていいでしょう。 解けるタスクの幅は未だ底が知れず、機械学習とは求められる能力も多少異なることからソフトウェアエンジニアである私の周りでも大きな変化が起きていると感じます。
LIFULLでもこの変化をコーポレートメッセージである「あらゆるLIFEを、FULLに。」の実現に繋げるべくジェネレーティブAIプロダクト開発室が新設され、一発目としてLIFULL HOME'SのChatGPT Pluginをリリースしました。
さて、我々KEELチームはKubernetesベースの内製PaaSであるKEELを開発・運用するチームです。
我々にはプラットフォームというレバレッジの効くソフトウェアを通して「あらゆるLIFEを、FULLに。」の実現にスケーラブルに貢献する責任があります。
これまでKEELではコードジェネレータによるPaaS体験を軸に、可観測性やセキュリティ, デリバリーパイプライン, MLOpsから各種データストア・認証基盤に加えてアプリケーションの参考実装の提供に至るまで必要なことはすべてやってきました。
LLMという新たなパラダイムでも同様にプラットフォーマーとしてやれることがあるはずです。
Platform Engineeringからのアプローチということで、社内でのLLM活用を促進するためにこれまでやってきたことを紹介します。
ベクトルデータベースの提供
ベクトルデータベースはLLMの文脈では長期記憶を実装するために利用されるデータストアで、個人的にこれから最も熱い領域の一つだと思っています。
LLMはモデルによって扱えるトークン数に限界があり、単体ではこのトークン数を超えて処理することはできません。
つまり、例えばChatGPTで長期のやり取りに応じた返答をさせたり、LLMに対して未知の大量の前提知識を与えてそれに基づいた回答をさせられないということです。
これを解決するために用いられる手法がベクトル表現を用いたSemantic searchです。 Semantic searchは情報検索の分野で知られる手法で、キーワードで検索するKeyword-based searchに対してベクトルによって表現された"意味"で検索します。
LLMの長期記憶は、あらかじめ長期に及んだやり取りや前提知識をベクトル表現に変換してベクトルデータベースに格納しておき、同様に変換したクエリからSemantic searchでそれらを取り出すことによって実現されます。 繰り返しLLMを呼ぶことで複雑なタスクを解くAutoGPTにも長期記憶が必要でありこの手法が用いられていました。
モデルに対する知識の追加はFine-tuningでも実現可能なはずですが、私の理解では過去の学習を忘却してしまうCatastrophic Forgettingなどが問題で期待する性能が出づらいという認識です。 そのため、LLMに複雑なタスクを解かせるための長期記憶を実装するにはベクトルデータベースは不可欠であり、プラットフォームとして提供することを決めました。
Redis
これまで内製PaaSであるKEELではいくつかのデータストアをコードジェネレータ経由で利用できるようにしてきていて、Redisもその中の一つです。
RedisにはRediSearchという全文検索に対応するモジュールがあり、これはSemantic searchにも対応しています。 そして、このRediSearchをはじめとした高品質なモジュールをバンドルしたRedis Stackというパッケージがあったため、素直にこれに差し替えるだけで既存のRedisクラスタをSemantic searchに対応できそうだということでまずはRedisから始めました。
提供していたRedisクラスタはRedis SentinelによるクラスタリングとHAProxyによるLeaderのService Discoveryによって実現されていて、書き込みがスケールしないことから主にキャッシュなどのRead Heavyなワークロード向けに提供しています。 LLMの長期記憶に関しても読み込みクエリが支配的であると考えられたためこれをRedis Stackに差し替えるだけで問題ないと判断しました。
しかし、ご存じの通りRedisは高速であることのトレードオフとしてすべてのデータをメモリに載せる設計です。 AutoGPTなどから利用されるデータの生存期間が明確な長期記憶としては問題ありませんが、ドメイン知識を記憶させて自社独自の回答をさせるためには膨大なメモリが必要となってしまいます。
取り扱うデータ量の増加によってこの問題が顕著になってきたため次の選択肢を探しました。 それがQdrantです。
Qdrant
QdrantはSemantic searchを備えたRust製の検索エンジンです。 対抗馬としてはMilvus, Weaviate辺りでしょうか。
QdrantはMilvus, Weaviateと比較して機能が少ない反面、構成が非常にシンプルでパフォーマンスに優れています。 前述の通り想定しているユースケースでは書き込みのスケールはそれほど必要ないため、動的なシャーディングや書き込みと読み込みのパスを分けるmicroservicesモードは不要でした。
(我々が得意なRustで書かれているので、構成がシンプルなこともあり何かあっても自分でどうにかしやすいというのもあります。)
これもRedisと同様にコードジェネレータから利用できるようにして提供しました。
KEELにはコードジェネレータがあるため、Kubernetesではあるもののインタフェースが固まるまではオペレーターパターンでは提供しておらず、コードジェネレータのインプットとなるyamlにこう書くだけでQdrantクラスタが起動するようになっています。
spec: feature: qdrant: enabled: true replicas: 3
このタイミングで適切なダッシュボード・アラートから運用ドキュメントまでがコードジェネレータによって自動生成されているのでこの作業だけで既にProduction Readyです。
コミュニティからHelm chartも提供されていましたが、厳格な SecurityContext や TopologySpreadConstraint, Topology Aware Routing, mTLSなど我々がKubernetes Manifestsに要求する基準を満たすことが難しいため、基本的にHelm chartは利用しない方針でやっています。
Embeddings APIのキャッシュプロキシの提供
ここまででLLMの長期記憶を実装するために、データの生存期間が明確なユースケース向けにメモリ上で高速なSemantic searchを実現するRedisクラスタと、メモリに乗りきらない知識を記憶するためのディスクをバックエンドとしたQdrantクラスタを提供できました。
今後もユースケースに応じてサポートするデータストアを増やしていくことになるはずで、そうなるとデータストア間の移行コストが気になります。 ベクトル表現であるEmbeddingsの生成には結局OpenAIのモデルを使うことになることが多く、愚直に新しいデータストアに再インデックスしてしまうと決して安くない金額がかかってしまいます。
そこでプラットフォームからのアプローチとして、OpenAI及びAzure OpenAI ServiceのEmbeddings APIのキャッシュを透過的に行うプロキシを開発しました。 キャッシュがなければUpstreamのAPIにリクエストしてその結果をキャッシュ、キャッシュがあればそのまま返すというよくあるやつです。
(この図はChatGPT PluginのShow Me Diagramsを利用して作りました。)
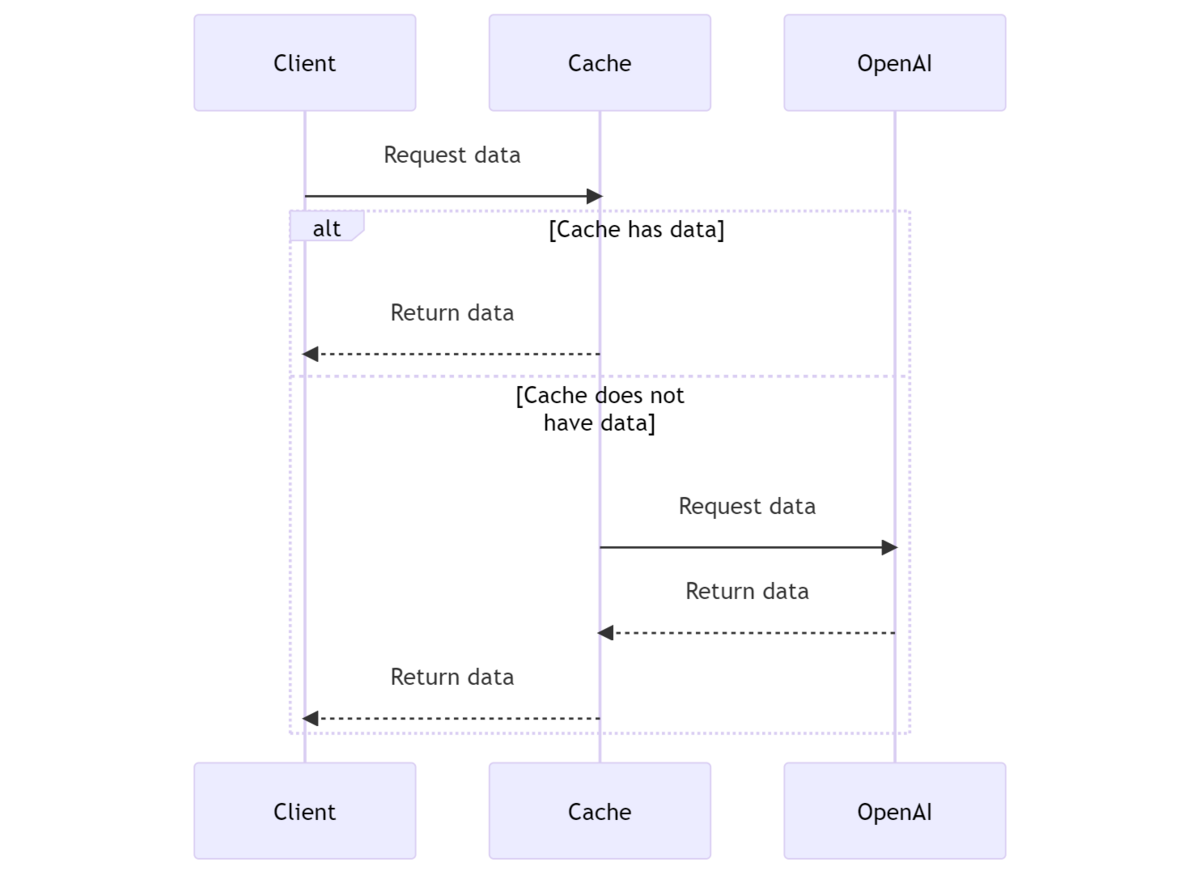
OpenAIの公式クライアントであるopenai/openai-pythonなどは OPENAI_API_BASE 環境変数でAPIの向き先を変更することが可能です。
インターフェースは揃えてあるので、これを利用して向き先をキャッシュプロキシに変えることでクライアントへの変更なしに透過的にキャッシュを挟むことができるといった具合です。
Embeddings APIのレスポンスはJSONなので素直にgzipしてオブジェクトストレージに保存するだけのシンプルなソフトウェアになりました。 Embeddingsを生成するために利用するモデルの名前がリクエストボディに入ってくるのでキャッシュのキーは普通にリクエストボディのハッシュ値でよくて、キャッシュのExpirationはオブジェクトストレージ側に任せてしまっています。
OpenAIとAzure OpenAI Serviceの差異はopenai.util.api_key_to_headerなどでOpenAIの公式クライアントが吸収してくれているのでこの辺をそのまま利用すると楽ができます。
我々はObservability Platformも提供する内製PaaSのチームなので、(布教も兼ねて)このキャッシュプロキシにもちゃんとOpenTelemetryを入れてUpstreamに投げられたトークン数の監視と分散トレーシングをしました。 OpenAIはAPI Keyごとに利用料を追えないため、このレイヤでトークン数を監視することで細かく利用料を確認することができます。
これをプラットフォームから提供することで、単なるデータストア移行のコスト削減だけでなくサービスをまたいだEmbeddingsの共有みたいなところも狙っています。
ChatGPT Retrieval Pluginの構築
LLMの長期記憶のユースケースとしてすぐに思いつくのはやはり社内のQ&A Botでしょう。 社内のドメイン知識をもとにChatGPTが回答できるようになれば、いわゆる社内質問窓口の一部を代替できるはずです。
そのためのソフトウェアをOpenAIがChatGPT Pluginの発表と同じようなタイミングで公開しています。 openai/chatgpt-retrieval-pluginです。
これはベクトルデータベースをバックエンドとして文書のインデックスとSemantic searchをするChatGPT Pluginで、PDFのパースなどLangChainのDocument Loaderのような部分も内包していて、これさえあればすぐにChatGPTに社内ドキュメントをもとにした回答をさせることができます。 これを適当な場所で動かして、社内ドキュメントをインデックスするだけでやりたいことができそうです。
ただ、この手の誰のJob Descriptionにも書かれていないような仕事は往々にして進みが悪くなりがちです。
我々が開発する内製PaaSであるKEELを利用すればすぐにでも動かすことができるため、社内のQ&Aフォーラムを運営していてRetrievalに関心があった二宮の協力も得ながらプラットフォームの一環としてこの仕事を始めました。
現在はQdrantをバックエンドにしたChatGPT Retrieval PluginがKEEL上で稼働しており、同様にKubernetesのCronJobで社内Q&Aフォーラムをはじめとした社内ドキュメントを定期的にインデックスするバッチプログラムが動いています。 それをSlack BotからLangChainのRetrieval QA経由で呼びだして、社内のドメイン知識をもとに回答するChatGPTを実現しました。
残念ながら今のところはChatGPT Retrieval Pluginはforkして利用してしまっており、運用上で見つかったいくつかの課題はタイミングを見てパッチを送るつもりではあります。
- QdrantのReplication FactorやShard数を外から与えることができない(datastore/providers/qdrant_datastore.py#L275)
- (Redisを代わりに使う場合)Connection PoolなしにRedisの接続を持ち回すため
retry_on_errorを書かないと接続先の入れ替わりなどに対応できない(datastore/providers/redis_datastore.py#L92) - Chunk分割のロジックで日本語の文末が考慮されていない(services/chunks.py#65)
- Chunkのサイズは言語ごとのトークン数の消費具合を考慮して決定した方がよい(services/chunks.py#L15)
などです。
コマンドラインツールでのLLM活用
一気に毛色が変わってコマンドラインツールでLLMを利用した機能を提供している話です。
我々はコードジェネレータをはじめ内製PaaSのKEELを利用するために便利な機能が詰まった keelctl というコマンドラインツールを提供しています。
keelctl self-update というコマンドで簡単に最新にバージョンアップすることができ、コードジェネレータである keelctl gen を実行するとKubernetes ManifestsからGitHub Actions, 運用ドキュメントまで最新のベストプラクティスが生成されるというようなソフトウェアです。
こうした機能を持つため大抵の開発者の手元には常に最新の keelctl が入っているような文化を作ることに成功しました。
これによりプラットフォーマーとしてKubernetesクラスタ経由での機能提供だけでなく、コマンドラインも握れているため開発者のローカルの環境にも影響力を持つことができています。
活用を促進するならまずは背中を見せようということで、その keelctl では keelctl llm というサブコマンドでLLMを利用した機能をいくつか提供してきました。
今回はそのうち keelctl llm conventional-commits というConventional Commits形式のコミットメッセージを自動生成する機能を紹介します。
Conventional Commits形式のコミットメッセージの自動生成
正直この辺の開発環境でのLLM活用を考えると大抵GitHub Copilotとバッティングすることになります。 しかしConventional Commitsは組織でルールを微調整したかったりするため自前でやる価値があると判断しました。
Conventional Commitsとは人間と機械が読みやすく、意味のあるコミットメッセージにするための仕様です。
人間が手書きするには少し体力のいる仕様で、ルールも細かく定義されているためこれの自動生成はLLMが得意そうなタスクです。 プロンプトは後述しますが、トークン数節約のためLIFULLでは不要な制約を少し消しているのとコミットの型を明示しています。
自動生成の機能としては非常に単純で、あらかじめ与えておいたプロンプトをもとに、標準入力として受け取った git diff の出力結果からConventional Commits形式のコミットメッセージの候補を指定した数だけ生成し、Fuzzy Finderで良さそうなコミットメッセージを選択するとそれを標準出力するというものです。
このように使います。
$ git diff --cached | keelctl llm conventional-commits --select 3 | git commit -F -

プロンプトの role: system はこんな感じです。
Please create an appropriate commit message for the given diff according to the following specifications. --- ## Specifications 1. Commits MUST be prefixed with a type, which consists of a noun, feat, fix, etc., followed by the OPTIONAL scope, and REQUIRED terminal colon and space. 2. A scope MUST be provided after a type. A scope MUST consist of a noun describing a section of the codebase surrounded by parenthesis, e.g., fix(parser): 3. A description MUST immediately follow the colon and space after the type/scope prefix. The description is a short summary of the code changes, e.g., fix: array parsing issue when multiple spaces were contained in string. 4. A longer commit body MAY be provided after the short description, providing additional contextual information about the code changes. The body MUST begin one blank line after the description. 5. A description MUST be kept within 72 characters. 6. The first letter of a description MUST be capitalized. 7. A longer commit body MUST be kept within 400 characters. 8. MUST not contain any footer. 9. The appropriate type/scope MUST be determined from the diff. 10. The commit message MUST be written in English. ## Available Types - feat: Addition of new features - fix: Bug fixes - docs: Documentation-only changes - style: Changes that do not affect the meaning of the code (whitespace, formatting, missing semicolons, etc.) - refactor: Code changes that do not modify existing functionality or add new functionality, such as changing variable or function names - perf: Performance improvements - test: Modifications or additions to existing tests - chore: Changes that are not important to developers, such as changes to the build process or library dependencies
この機能を配布するにあたって、利用者の手元に OPENAI_API_KEY がないと使えないということは避けたいです。
API Keyの共有はセキュリティ的に論じるまでもないですし、それぞれがAPI Keyを発行することは利用のハードルが高すぎます。
そこで、我々が用意している認証基盤を利用することにしました。 内製PaaSのKEELではLIFULLで利用しているSSOのサービスをIdPとしたSAMLの認可プロキシを用意しています。
この認可プロキシのUpstreamとしてOpenAIのAPIを設定して、このプロキシのレイヤでOpenAIのAPI Keyをヘッダに入れることでOneLoginでログイン済みのユーザであれば OPENAI_API_KEY なしにOpenAIのAPIが利用できます。
認可プロキシなのでログも取れており、これもキャッシュプロキシの章で述べたOpenAIではAPI Keyごとに利用料を管理できない問題を解決できました。
ただしこの認可プロキシはCookieをもとに認可を行うため、Cookieを持たないコマンドラインからは素直に利用することができません。 こういう時にはよくある認証パターンを利用することができます。

- コマンドラインツールが
0.0.0.0:0でHTTPサーバとして待ち受ける(:0で待ち受けるとランダムな空いているポートを割り当てることができます) - コマンドラインツールが待ち受けているアドレスを
redirect_urlクエリ文字列に付与して<Authorization Proxy URL>/callbackをxdg-openで開く(xdg-openはコマンドラインからブラウザを開くためのプロトコルです) - Authorization Proxyで認可を行い必要に応じてSSOで認証する
- Authorization Proxyが認証済みのCookieの値をクエリ文字列に付与して
redirect_urlにリダイレクトする - コマンドラインツールが受けたリクエストのクエリ文字列からCookieの値を取得する
- そのCookieを利用して認可プロキシにリクエストを投げる
という流れです。
これにより、既に開発者の手元に入っているコマンドラインツールから一切の設定を必要とせずにLLMを利用した機能を提供することができました。
この機能は結構好評で、後続のリリースでConventional Commitsをもとにしたバグ発生率などのレポーティング機能も実装したこともあり、既に多くのチームでConventional Commitsが採用され始めています。 GitHub Copilotの隙間を縫っただけのような気もしますが、これで一つLLM活用の方向性を示すことができたと思います。
今後の展望
LLM活用促進に向けてPlatform Engineeringから行ってきたアプローチをいくつか紹介しました。 ですが、実際のところLLMのインパクトに対しては社内の活用はまだ不足していると感じています。
ジェネレーティブAIプロダクト開発室は新設されたものの、LLMは陳腐な言い方をすれば民主化されたAIであり、専任部署だけのものではないどころかソフトウェアエンジニアに限らず多くの人が活用してしかるべきです。
今後もプラットフォーマーとして活用の下支えをしながら一層LLMを「あらゆるLIFEを、FULLに。」の実現に繋げていこうと思います。 直近では組織にまだ活用のイメージが不足していると思っていて、AI戦略室と主要なアプリケーション開発者とともに、実際のアプリケーションでLLMを利用する生きた参考実装を用意しようと動いています。
個人的にはそろそろ(概念としての)AutoGPTによるアプリケーション実装の自動生成と真剣に向き合う頃合いかなとも思っています。
Platform EngineeringではこれまでSREを中心に価値あるプラクティスを組織に適用してきました。 これはプラットフォームがレバレッジの効くソフトウェアであるからで、LLMのような新たなパラダイムが出てきた時にそれを組織に適用する責任もプラットフォーマーにはあるはずです。
そして我々KEELチームはその結果として「あらゆるLIFEを、FULLに。」の実現にスケーラブルに貢献していくことを目指しています。 そんなKEELチームにもし興味を持っていただければ是非カジュアル面談しましょう!