テクノロジー本部のyoshikawaです。
最近のLIFULLでは、自社が所有するデータの活用を目的に数多くの取り組みが実施されています。
今回はデータの発見可能性(Data Discovery)を向上させるための基盤構築を目指して実施したPoC(Proof of Concept)とそのOSSの選定について紹介します。
当初は「自社データの再利用性を高めたい」という広い意味を持った要件で開始したプロジェクトでしたが、
Data Discoveryがボトルネックになっていると判明し、解決策としての基盤構築に向けてPoCを実施することとなりました。
現場の課題調査からOSSの選定と試験運用まで一連のトピックをまとめていきます。
初期フェーズ: 現場調査と課題抽出
昨年秋、「自社データの再利用性を高めたい」という目的とともにプロジェクトがスタートしました。
筆者をはじめ、プロジェクトメンバーにはデータエンジニア的なバックグラウンドを持つ人はおらず、まずは現場調査を通じ探索的に解決策を導出することとなりました。
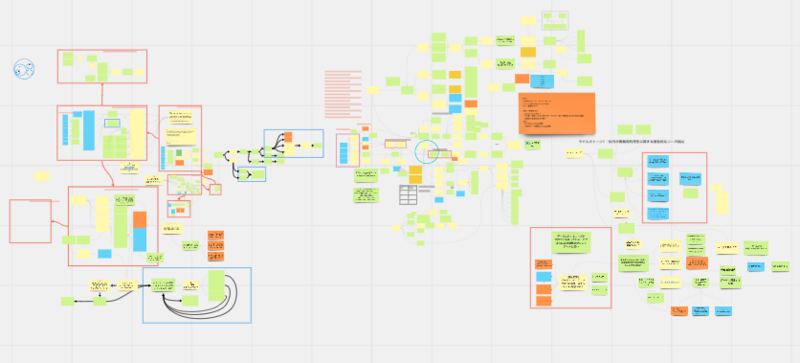
ディスカッションや調査の際には記録を手続き的なドキュメントとして残すのではなく、IBIS(Issue Based Information System)という手法と
オンラインホワイトボードのMiroを活用することで、議事録作成をDialogue mapping化しDAGとして残しました。
現場調査のフェーズは2ヵ月にわたり、なおかつ多くのステークホルダーに対して実施したため、
過去のやりとりと現在の関心事との関連を視覚的に把握しやすい形式で議論を行うことで議論の発散と収束を視覚化できたのは効果的でした。
FAIR原則
データの再利用性を高めたいという観点でスタートしたものの、この時点ではデータエンジニアリングの観点が不足していたこともあり最終的な成果の定義に難儀してしまいました。
民間企業だけではなくアカデミックにおいてもデータ活用の問題は存在していると考えリサーチを行ったところ、データ共有の原則であるFAIR原則を発見しました。
FAIR原則を知り、これまでに自分たちが焦点を当てていたデータの再利用性とは、相互に関連する4つの原則のうち1つに関連するものでしかないと認識しました。
これ以降は、データ活用にまつわる複数の問題を念頭に置きつつ、ディスカッションや後続となるインタビュー調査を実施しました。
データ利用の現場から抽出した課題
データ分析者やAIエンジニア、プロダクト開発を行うアプリケーションエンジニアや企画職などデータに関連する職種の方々に協力いただきインタビュー調査を行いました。
その結果を要約すると、下記のような課題が得られました。
データの格納場所やデータの情報(メタデータ)あるいはデータの存在自体が不明、または特定のチームや個人のナレッジとして埋没している
データの派生系が多く、利用価値のあるデータ・起源となるデータなどユニークなデータが発見できない
発見したデータが更新されているのか、誰が管理しているのかが不明で利用開始するまでに問い合わせが発生する
いわゆるデータのサイロ化に起因する問題が目につきます。
これらインタビュー調査の結果を踏まえ、あるべき解決策は静的なドキュメンテーションや属人的な助け合いの仕組みの強化ではなく、
「自動で最新の状態に追従可能で、統一された形式に沿って管理・運用されたデータが入手可能な基盤」であると結論づけました。
ボトルネックの特定と解決策の選定
ここまでの調査は現場の開発者・分析者へのインタビューなどを通じてボトムアップ的に行われてきました。
調査で得られた生の課題の集まりに対して優先的に取り組むべき課題と解決策を選ぶために、書籍"The Self-Service Roadmap"にて導入されていた考え方を取り入れました。
The Self-Service Roadmapにおいては、データ活用の主たる指標とも言える"Time to insight"(知見を得るまでの時間)を
"Discover", "Prep", "Build", "Operationalize"の4つのフェーズに分割することが提唱されています。
自分たちの調査によって集められた課題は、Discoverのフェーズ、特にデータセットあるいはそのメタデータの検索の課題に該当すると判断しました。
つまり"Data Discovery"こそが開発・分析現場のボトルネックとなっており、優先的に取り組むべき課題であると判明したのです。
PoCの開始
The Self-Service Roadmapにおいてself-service data platformが立ち行かなくなるアンチパターンとして、
問題を理解しないまま技術にだけ投資してしまうことと、一度に多くの問題を解こうとすることが挙げられています。
アンチパターンに陥らないためにも今回のプロジェクトではData Discoveryに焦点を当て、
これを持続的に解決可能な基盤を導入すべく、技術選定とそのPoC(Proof of Concept)から始めていきます。
OSSの選定
近年、海外を中心としてModern Data Stackという言葉とともに最新のデータ基盤周辺技術に注目が集まっています。
日本でも注目されているdbtのブログにて、Modern Data Stackの来歴とともに展望を読み取ることができます。
Data Discoveryの分野だけでなく、Modern Data Stackを構成する技術は多岐に渡り、
解決したい問題領域や抱えるデータセットの量、事業フェーズなどの制約条件に沿って適切な技術を選定する必要があります。
今回の場合は「"多様なデータソース"に対して"Data Discovery"を向上させるための"基盤(Platform)"の"PoC"を行いたい」という制約に基づき、
LinkedInとAcryl DataによるOSSである"Datahub"を選びました。
Data Discoveryの向上を目指せるMetadata Platform系のOSSにはAmundsenやApache Atlas、Open Metadataなどがありますが、
PoC期間内での構築しやすさ・運用可能性、利用者(社内開発者・分析者)向けのUXや機能性を考慮した結果、Datahubを選定しました。
OSSの採用以外の選択肢には、社内で利用しているGoogle CloudのData Catalogを充実させるという選択肢もありましたが、
LIFULLのデータセットはAWSやGCPなど複数のインフラで稼働しているため、中立的なDatahubを試用することとなりました。
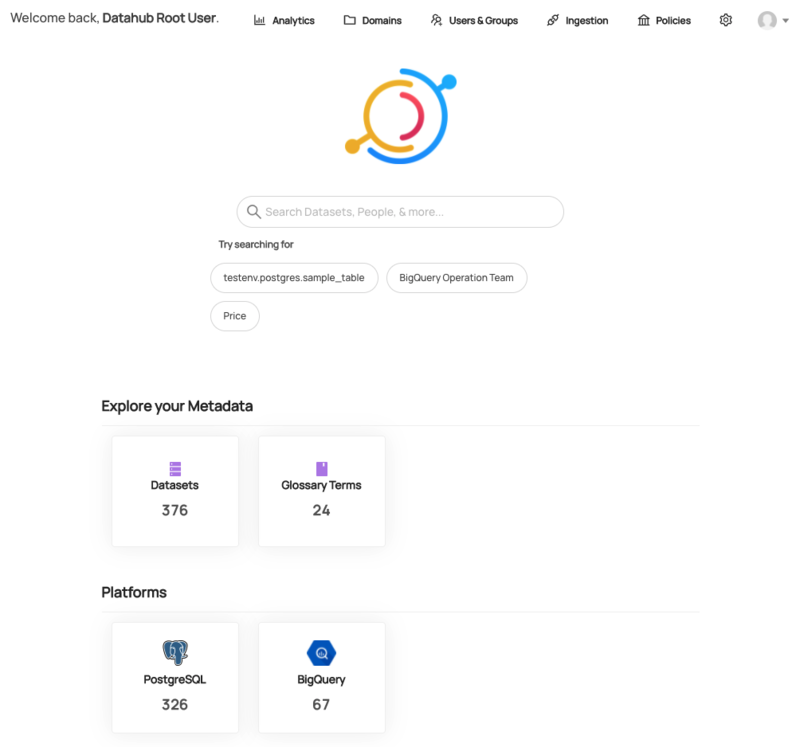
Datahubとは
公式ドキュメントでは下記のように説明されており、多様で複雑なデータエコシステムにおけるMetadata PlatformとしてData Discovery, Data Observability, Federated Governanceを実現させることが特徴として挙げられています。
Data ecosystems are diverse — too diverse. DataHub's extensible metadata platform enables data discovery, data observability and federated governance that helps you tame this complexity.
Data Discoveryという点ではElastic Searchによるメタデータの検索やWebブラウザのようなUI、Datahub独自のシンプルで拡張性のあるメタデータスキーマによって実現されています。
このようにしてプロダクト開発者や分析者などデータ利用者にとってはシンプルな機能を提供しつつも、
Push型のデータ更新アーキテクチャによる最新のデータへの追従やData Lineageの取得によるObservabilityの確保と、
AWSのIAMのようなRBACによりFederated Governanceの実現を目指すことができ、継続的な運用に耐えうるカタログスペックを有しています。
また、DatahubではQuick Start用のDocker Imageやhelm chartsも用意されており、ローカル環境での試用やPoCが容易に実現可能です。
今回のPoC期間中でもhelm chartsを利用し、LIFULLの検証用Kubernetes環境上に1日程度でデプロイできました。
Metadata ingestion
RDB(MySQL,Postgres,etc),DWH(BigQuery,Snowflake,etc),BI(Tableau, Looker)など多岐にわたるデータソースから、カラムの物理名やスキーマ情報などのmetadataのingestionが可能です。
ingestされたmetadataに対してはUIやAPI経由で編集することが可能で、データに関するナレッジなどTeam Metadataも集約することが実現できます。
PoC期間中ではFederated Governanceの観点を検証しきれませんでしたが、基盤の管理者がingestionを中央集権的に管理・実行するのではなく
データソースに近いプロダクト開発エンジニアやデータソース運用者がDatahub上のmetadataのOwnerとなることで、
自分達のTeam Metadataは自分達で管理しつつ横断的なプラットフォームで第三者が入手・検索可能にし、self-serviceなデータ基盤を実現できるのではないかと考えています。
例えば、DDDにおけるユビキタス言語を制定した後はDatahub上に載せて、チーム内外の認識の齟齬を減らせることが期待できます。
PoCの評価指標
Datahubによって実現されるData Discovery Platformが本当に現場のData Discoveryを実現するかを評価することに加え、
大元の課題であったデータ活用の促進を実現できるかを検証するために、いくつか設問を用意しData Discovery Platformの利用者にアンケートをお願いしました。
例えば以下の2つです。
設問1. Datahubで構築したData Discovery Platformは、欲しいデータを発見するまでの時間を短縮するか?
設問2. Datahubで構築したData Discovery Platformは、データを発見してからデータを活用開始するまでの時間を短縮するか?
The Self-Service Data RoadmapにおけるDiscoverにおけるメトリクス:"Time to find"への貢献度を設問1で収集し、
Discoverというmilestoneを含めたデータ活用開始までの時間短縮への貢献度を設問2として収集しています。
別途、性能評価やマシンリソースの消費度合い、費用など非機能的な要件の評価も行います。
PoCの結果
社内のデータ基盤エンジニア・データ分析者・アプリケーション開発者・技術マネージャーなどにData Discovery Platformは利用され、アンケートを実施いただけました。
その結果、設問1については9割が好意的な回答で、設問2については好意的な回答が5割、否定的orわからないという回答が5割でした。
Data Discovery Platform導入への期待
設問1で好意的な回答が大半を占めたことから、Data Discovery Platformを意図して構築されたプラットフォームが
現場のData Discovery向上に寄与することが立証できたと言えます。
データ発見という観点で既存の社内ツールや技術基盤に対する競合優位性があったことは確かですが、
今後全社的に運用する場合、ingestするデータセットが増加し玉石混合なmetadataを持ってしまうリスクもあるので注意は必要です。
Data Discovery Platformはあくまでも必要条件
一方、設問2では半数が「いいえ」あるいは「わからない」など好意的とは言えない回答であったことから、
Data Discovery Platformの実現はあくまでデータ活用のための必要条件であり、十分にデータを活用するには他にも解決すべき課題があると考えています。
ただし好意的な回答が少なかった外部要因として、PoC期間に十分なmetadataを用意できなかったという要因もあるので、
ingest自体を効率化するような仕組みを検証していきたいと考えています。
これからの展開
今回のPoCを経てData Discovery Platformの導入が開発現場・分析現場のデータ活用を促進する一歩となることを立証できました。
ただ、あくまでPoCが成功したに過ぎず本格的な稼働に向けては運用面での課題も存在します。
魅力的な技術や目新しい技術の多いModern Data Stackですが、"right tool for the right job"を原則としてこれからの基盤構築を行っていきたいところです。
求人情報
LIFULLではエンジニアの募集をしており、カジュアル面談も実施中です。
募集中の職種など詳細は下記をご覧ください。