テクノロジー本部の yoshikawa です。
普段の業務では全社データ基盤の開発や技術検証、ビジネスサイドのデータ活用支援を行っています。
本記事では、Google CloudのDataplex(主にData CatalogとData Lineage)を活用したデータマネジメント及びその支援に関する事例を紹介します。
また関連して、データ開発の質とスピードを高めるべくCloud Composerとdbt(dbt Core)を採用し、DWH(データウェアハウス)/DM(データマート)構築基盤を刷新する取り組みについても紹介します。
全社データ基盤の概観
LIFULLの全社データ基盤はBigQuery(Google Cloud)を中心としつつETL処理にStep Functions(AWS)などを利用し構成されています。
全社データ基盤には基幹サービスであるLIFULL HOME'S上のログデータや地理情報マスターデータなどのデータソース、それらを事業・用途別に集計・加工したDWH(データウェアハウス)/DM(データマート)など、様々な出自・用途のデータが集約されています。
記事執筆時点での規模は容量にして数百TB、テーブル数にして1万以上と大量のデータが蓄積されており、今もなおデータ量が増加しています。
そうした大量のデータはBI経由で各部署・プロジェクトの指標として定期的に参照されたり、施策の効果測定や検証などアドホック分析、機械学習などに活用されています。
全社データ基盤ができるまで、そしてこれから
数年前、今の全社データ基盤が構築される前はデータ活用に関して下記のような課題がありました。
- クラウドサービスやDBにデータが散在(サイロ化)している
- セキュリティの観点からデータを抽出可能な人が限定されている
- データを使う人(アナリスト、企画、etc)と、データを抽出できる人(エンジニア)が別なので、手戻りが頻発しデータを使うまでの効率が悪い
そうした課題を解決すべく今の全社データ基盤が構築され、BigQueryへのデータ集約やIAMによる権限管理によって課題は解決されてきました。
(全社データ基盤が構築されるまでの沿革は過去のブログからご覧になれます。)
利用実績の増加を遂げつつデータを蓄積し続けている全社データ基盤ですが、これからはデータを蓄積し誰でも利用できるようにするだけでなく、データの活用を通じ価値提供を促すことで、利益という形でも貢献できる基盤へと成長していくことが重要となります。
データマネジメントの必要性
現在、全社データ基盤が安定稼働している中でデータ活用に関して下記のような課題があります。
- データを利活用するステークホルダーの増加・多様化、およびそれに伴う要望の複雑化・多様化(人の問題)
- データを生成する/参照するシステムの増加・複雑化、およびそれに伴う全体統制の難化(システムの問題)
- データ量の増加・管理の複雑化に伴うデータ品質維持の問題(データの問題)
全社データ基盤が構築される前と比べると業務プロセスの一部分としてデータを活用する際の問題だけではなく、データを扱う人や組織のリテラシーやガバナンス、中長期的にデータ活用を継続していく上での品質の維持や管理コストに関する課題が顕在化しています。
そのため、システムの一つとしてデータ基盤を開発し発展させるだけでなく、人・組織の問題へと越境することで上手くデータ活用をし続ける取り組み→データマネジメントが今の全社データ基盤で必要とされています。
データマネジメントの領域
データマネジメントには多様な領域が存在するとされています。
データマネジメントの知識体系をまとめた書籍として『DMBOK』が有名ですが、データガバナンスを中心とした「DAMAホイール図」と呼ばれる図にデータマネジメントに関する知識領域が定義されています。
(詳細は書籍かデータマネジメント協会 日本支部のホームページをご覧ください)
全社データ基盤においても、データセキュリティやドキュメントとコンテンツ管理、メタデータ(カタログ化)をはじめとした領域でデータマネジメントの取り組みが行われています。
それらの取り組みについて以降で紹介していきます。
データマネジメントをエンジニアとして支援する
データマネジメントはデータの生成や基盤に携わるデータエンジニアだけではなく、CDOやデータ基盤・統括に関連するマネージャー、データを活用するアナリストやデータサイエンティストなど多様なステークホルダーと連携し進めていきます。
筆者はデータマネジメントに必要とされる技術(Google Cloudのサービスが中心)についての検証や、ビジネス職(データスチュワード)への技術的な支援・提案といった形で携わっています。
データスチュワードの発足
先の課題として述べたようにステークホルダーの増加や多様化により、データエンジニアだけでデータに関する要望に応えることが難しくなりつつあります。
そこでLIFULLでは昨年末からデータ整備やデータ活用に関する相談窓口を担う役割としてデータスチュワードが発足しています。
Dataplexの活用
冒頭でお伝えしたように、全社データ基盤はGoogle CloudとAWS両方を利用して構成されています。
データ利用者にとって中心となるのはBigQueryであるため、データに関する情報(メタデータ、データ品質、セキュリティレベル、etc)はGoogle Cloudに集約するという流れになりつつあります。
データマネジメントの文脈において重要となるサービスはDataplexです。
DataplexにはLake、Zone、Assetという論理的な概念を使い、各ストレージ(データレイク、DWH、DM)上のデータをドメイン別に一元的に管理できる機能をはじめ、カタログ機能(これまでのData Catalog)や、データリネージ機能など、データガバナンスおよびデータマネジメントの観点で有用な機能が存在しています。
多様な機能が存在していますが、中長期的なデータマネジメントに貢献するか、および現在のデータスチュワードのユースケースに貢献するかを念頭にいくつかの機能を利用しています。
データのカタログ化と用語集
昨年の夏からデータカタログを利用し始め、現在ではデータスチュワードによるカタログ化(=タグ付けやドキュメンテーション)が進行しています。
中長期的な目標として全てのデータに対してのカタログ化を視野に入れていますが、現在は新規作成されたデータや戦略上重要とされるデータを優先的にカタログ化しています。
カタログ化において注目している機能は用語集(Dataplex business glossaries)です。(記事執筆時点ではpreview版です)
利用イメージは下記のGoogle Cloud Blogをご覧いただけると良いかと思います。
文字通り、事業/ビジネスに関する用語集を作成できる機能ですが、タグテンプレートのようにデータと関連づけを行うこともできます。
全社データ基盤では、Dataplex business glossariesが利用可能になる前からドメイン知識などのビジネス用語とデータとの関連づけを構想していました。
当時はタグテンプレートでの実現を予定していましたが、Dataplex business glossarieはタグテンプレートと比べ以下の点で利点があり、データ整備実施者とデータ利用者の両方にとってメリットがあると考えています。
- データに対する用語の関連付けや、用語間の関連付けがGUI上で容易に行える=整備が楽
- Data Catalogの検索結果上のスキーマタブで、内容を簡単に把握できる(下図を参照)=欲しい情報が見つけやすい
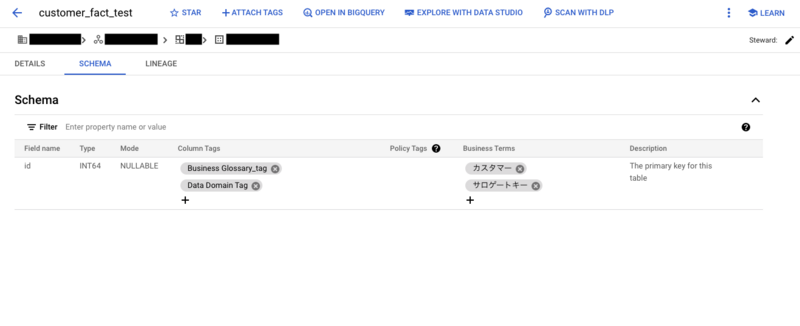
まだpreview段階の機能ではありますが、データソース(BigQuery)と近いところにデータの仕様(Dataplex business glossaries)を蓄積させ、データ利活用者およびデータスチュワードの認知負荷を軽減し、データ利活用の体験を向上させていければ理想的だと考えています。
データリネージの活用
筆者は昨年夏のデータカタログの利用開始と同時期にデータリネージの実現についても検証しています。
その結果として、Audit LogsとINFORMATION_SCHEMAから取得可能なテーブル定義とジョブ実行情報を元データとし、Streamlitとpyvisを用いて可視化するデータリネージアプリを実装しました。
詳細は過去のブログよりご覧いただけます。
データリネージアプリは半年程度運用し、その間に下記のようなユースケースが生まれました。
- 施策によるデータソース定義変更の影響範囲調査
- 不要データセット削除による影響範囲調査
そんな中、Google Cloudから公式のデータリネージ機能がアナウンスされ利用できるようになりました。(記事執筆時点ではpreview版の機能を含みます)
機能の詳細は上記公式ドキュメントの通りですが、使用感としてはこれまでに生じた影響範囲というユースケースに対しては対応できると考えており、BigQueryのタブからもアクセスできることから、アドホックな分析でSQLを書きながら関連するデータがないか探索するといった用途にも適していそうです。
記事執筆時点では機能面の充足や費用面への影響を中心に検証を行っており、本番環境への適用に向けて準備をしています。
カスタマイズ性という観点では、自前で容易したデータリネージアプリが勝る場面もありそうですが、先のDataplex business glossariesとあわせ、データに関する情報をGoogle Cloudへと集約することでSSoT(Single Source of Truth)を構築できる良い機会と考えています。
DWH/DM構築基盤の刷新
こちらはデータマネジメントというよりエンジニアリング寄りの内容ですが、5年以上にわたって稼働しているDWH/DM構築基盤の刷新も進行しています。
現状のETL処理基盤はデータパイプライン構築にLuigi、ワークフロー実行環境にStep Functions(AWS)などを採用して構成されています。
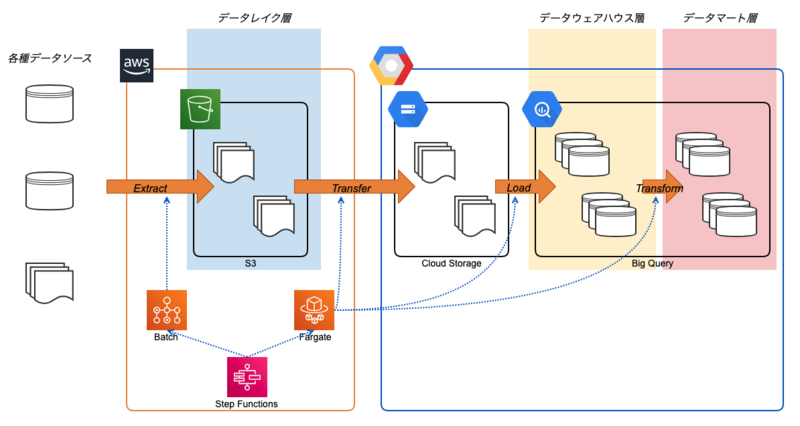
当時からデータエンジニアリングに関するツールや知見は進化し、開発速度や開発者体験を向上させる仕組みが整ってきたことから、現行の構成からワークフローの実行および管理の基盤としてCloud Composer、SQL開発およびデータモデリング用にdbt(dbt Core)を採用した基盤へのリプレイスの検証が開始しました。
その他の採用技術の候補としてArgo Workflows(on GKE)やDataformも検討しましたが、 マネージドサービスの恩恵を受けながらも、開発者体験を上げつつデータ開発を効率化できるようComposerとdbtという組み合わせを採用しました。
記事執筆時点では一部処理での検証を実施している段階ですが、下記のようなメリットを感じています。
- SQLとワークフロー実行設定が分離されるようになり、SQLにデータ・テーブルに関する仕様が集約されるようになった
- dbtがSQLの依存関係を解析してくれるため、SQL実行順序の制御が手軽になった
- スキーマ定義やワークフロー実行制御において手動実行していた開発フローが自動化された
まとめ
LIFULLの全社データ基盤ではGoogle Cloudを活用しデータマネジメントおよびその支援を進めています。
本記事ではその中でもデータカタログ(Dataplex business glossaries)を利用したカタログ化、データリネージ機能を採用した影響範囲調査の負荷軽減、開発者体験・開発速度の向上を目的とした既存ETL処理基盤の刷新についてお伝えしました。
本記事では紹介しきれなかったデータマネジメントに関連する取り組み(データ品質、データセキュリティなど)も多くあるため、後続のクリエイターズブログでお伝えできればと思います。
最後に、LIFULLではエンジニアを募集しています。カジュアル面談のご応募や現在募集中の職種については下記をご覧ください。